Establishing Connectivity to Hadoop
Overview of Establishing Connectivity to Hadoop
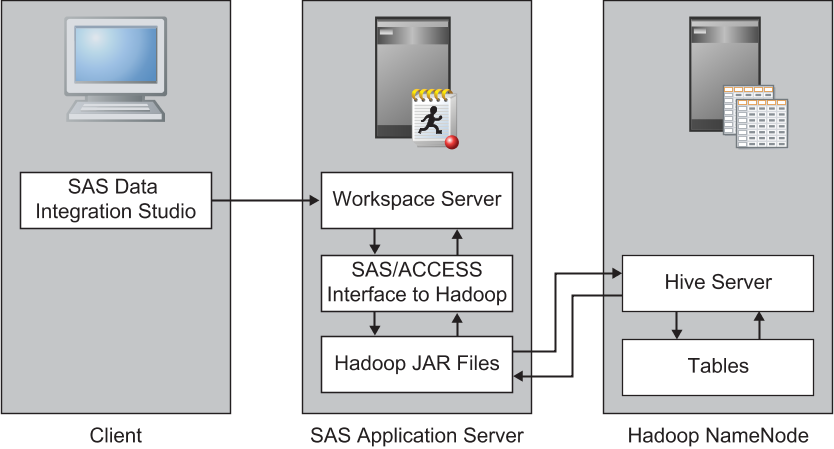
The following figure
provides a logical view of using the SAS/ACCESS Interface to Hadoop
to access a Hive Server. The Hive Server is shown running on the same
machine as the Hadoop NameNode.
Setting up a connection
from SAS to a Hadoop Server is a two-stage process:
This example shows the
process for establishing a SAS connection to a Hive Server. In order
for the SAS/ACCESS Interface to connect with the Hive Server, the
machine that is used for the SAS Workspace Server must be configured
with several JAR files. These JAR files are used to make a JDBC connection
to the Hive Server. The following prerequisites have been satisfied:
-
installation of SAS/ACCESS Interface to Hadoop. For configuration information, see the Install Center at http://support.sas.com/documentation/installcenter/93 and use the operating system and SAS version to locate the appropriate SAS Foundation Configuration Guide.
Stage 1: Register the Hadoop Server
To register the Hadoop Server, perform
the following steps:
-
Connection Properties
HadoopAuth(You might need to create a new authentication domain. For more information, see How to Store Passwords for a Third-Party Server in SAS Intelligence Platform: Security Administration Guide.) Click New to access the New Authentication Domain dialog box. Then enter the appropriate value in the Name field and click OK to save the setting.
Stage 2: Register the Hadoop via Hive Library
After
you have registered the Hadoop Server, register the library. To register
the Hadoop via Hive library, perform the following steps:
-
Examine the final page of the wizard to ensure that the proper values have been entered. Click Finish to save the library settings. At this point, register tables as explained in Registering and Verifying Tables.