The %BOXCOXAR macro finds the optimal Box-Cox transformation for a time series.
Transformations of the dependent variable are a useful way of dealing with nonlinear relationships or heteroscedasticity. For example, the logarithmic transformation is often used for modeling and forecasting time series that show exponential growth or that show variability proportional to the level of the series.
The Box-Cox transformation is a general class of power transformations that include the log transformation and no transformation as special cases. The Box-Cox transformation is
The parameter ![]() controls the shape of the transformation. For example,
controls the shape of the transformation. For example, ![]() =0 produces a log transformation, while
=0 produces a log transformation, while ![]() =0.5 results in a square root transformation. When
=0.5 results in a square root transformation. When ![]() =1, the transformed series differs from the original series by
=1, the transformed series differs from the original series by ![]() .
.
The constant c is optional. It can be used when some ![]() values are negative or 0. You choose c so that the series
values are negative or 0. You choose c so that the series ![]() is always greater than
is always greater than ![]() .
.
The %BOXCOXAR macro tries a range of ![]() values and reports which of the values tried produces the optimal Box-Cox transformation. To evaluate different
values and reports which of the values tried produces the optimal Box-Cox transformation. To evaluate different ![]() values, the %BOXCOXAR macro transforms the series with each
values, the %BOXCOXAR macro transforms the series with each ![]() value and fits an autoregressive model to the transformed series. It is assumed that this autoregressive model is a reasonably
good approximation to the true time series model appropriate for the transformed series. The likelihood of the data under
each autoregressive model is computed, and the
value and fits an autoregressive model to the transformed series. It is assumed that this autoregressive model is a reasonably
good approximation to the true time series model appropriate for the transformed series. The likelihood of the data under
each autoregressive model is computed, and the ![]() value that produces the maximum likelihood over the values tried is reported as the optimal Box-Cox transformation for the
series.
value that produces the maximum likelihood over the values tried is reported as the optimal Box-Cox transformation for the
series.
The %BOXCOXAR macro prints and optionally writes to a SAS data set all of the ![]() values tried, the corresponding log-likelihood value, and related statistics for the autoregressive model.
values tried, the corresponding log-likelihood value, and related statistics for the autoregressive model.
You can control the range and number of ![]() values tried. You can also control the order of the autoregressive models fit to the transformed series. You can difference
the transformed series before the autoregressive model is fit.
values tried. You can also control the order of the autoregressive models fit to the transformed series. You can difference
the transformed series before the autoregressive model is fit.
Note that the Box-Cox transformation might be appropriate when the data have a common distribution (apart from heteroscedasticity) but not when groups of observations for the variable are quite different. Thus the %BOXCOXAR macro is more often appropriate for time series data than for cross-sectional data.
The form of the %BOXCOXAR macro is
%BOXCOXAR ( SAS-data-set, variable < , options > ) ;
The first argument, SAS-data-set, specifies the name of the SAS data set that contains the time series to be analyzed. The second argument, variable, specifies the time series variable name to be analyzed. The first two arguments are required.
The following options can be used with the %BOXCOXAR macro. Options must follow the required arguments and are separated by commas.
The value of ![]() that produces the maximum log likelihood is returned in the macro variable
that produces the maximum log likelihood is returned in the macro variable &BOXCOXAR. The value of the variable &BOXCOXAR is “ERROR” if the %BOXCOXAR macro is unable to compute the best transformation due to errors. This might be the result of large lambda
values. The Box-Cox transformation parameter involves exponentiation of the data, so that large lambda values can cause floating-point
overflow.
Results are printed unless the PRINT=NO option is specified. Results are also stored in SAS data sets when the OUT= option is specified.
Assume that the transformed series ![]() is a stationary pth order autoregressive process generated by independent normally distributed innovations.
is a stationary pth order autoregressive process generated by independent normally distributed innovations.
Given these assumptions, the log-likelihood function of the transformed data ![]() is
is
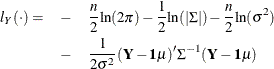
In this equation, n is the number of observations, ![]() is the mean of
is the mean of ![]() , 1 is the n-dimensional column vector of 1s,
, 1 is the n-dimensional column vector of 1s, ![]() is the innovation variance,
is the innovation variance, ![]() , and
, and ![]() is the covariance matrix of Y.
is the covariance matrix of Y.
The log-likelihood function of the original data ![]() is
is
where c is the value of the CONST= option.
For each value of ![]() , the maximum log-likelihood of the original data is obtained from the maximum log-likelihood of the transformed data given
the maximum likelihood estimate of the autoregressive model.
, the maximum log-likelihood of the original data is obtained from the maximum log-likelihood of the transformed data given
the maximum likelihood estimate of the autoregressive model.
The maximum log-likelihood values are used to compute the Akaike Information Criterion (AIC) and Schwarz’s Bayesian Criterion
(SBC) for each ![]() value. The residual mean squared error based on the maximum likelihood estimator is also produced. To compute the mean squared
error, the predicted values from the model are transformed again to the original scale (Pankratz 1983, pp. 256–258; Taylor 1986).
value. The residual mean squared error based on the maximum likelihood estimator is also produced. To compute the mean squared
error, the predicted values from the model are transformed again to the original scale (Pankratz 1983, pp. 256–258; Taylor 1986).
After differencing as specified by the DIF= option, the process is assumed to be a stationary autoregressive process. You can check for stationarity of the series with the %DFTEST macro. If the process is not stationary, differencing with the DIF= option is recommended. For a process with moving-average terms, a large value for the AR= option might be appropriate.