MEANS Procedure
- Syntax

- Overview
- Concepts
- Using
- Results
- Examples Computing Specific Descriptive StatisticsComputing Descriptive Statistics with Class VariablesUsing the BY Statement with Class VariablesUsing a CLASSDATA= Data Set with Class VariablesUsing Multilabel Value Formats with Class VariablesUsing Preloaded Formats with Class VariablesComputing a Confidence Limit for the MeanComputing Output StatisticsComputing Different Output Statistics for Several VariablesComputing Output Statistics with Missing Class Variable ValuesIdentifying an Extreme Value with the Output StatisticsIdentifying the Top Three Extreme Values with the Output StatisticsUsing the STACKODSOUTPUT option to control data
- References
Concepts: MEANS Procedure
Using Class Variables
Using TYPES and WAYS Statements
The TYPES statement
controls which of the available class variables PROC MEANS uses to
subgroup the data. The unique combinations of these active class variable
values that occur together in any single observation of the input
data set determine the data subgroups. Each subgroup that PROC MEANS
generates for a given type is called a level of that type. Note that
for all types, the inactive class variables can still affect the total
observation count of the rejection of observations with missing values.
When you use a WAYS
statement, PROC MEANS generates types that correspond to every possible
unique combination of n class
variables chosen from the complete set of class variables. For example
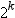
Ordering the Class Values
PROC MEANS determines the order of
each class variable in any type by examining the order of that class
variable in the corresponding one-way type. You see the effect of
this behavior in the options ORDER=DATA or ORDER=FREQ. When PROC MEANS
subdivides the input data set into subsets, the classification process
does not apply the options ORDER=DATA or ORDER=FREQ independently
for each subgroup. Instead, one frequency and data order is established
for all output based on a nonsubdivided view of the entire data set.
For example, consider the following statements:
data pets; input Pet $ Gender $; datalines; dog m dog f dog f dog f cat m cat m cat f ; proc means data=pets order=freq; class pet gender; run;
Computational Resources
PROC MEANS uses the same memory
allocation scheme across all operating environments. When class variables
are involved, PROC MEANS must keep a copy of each unique value of
each class variable in memory. You can estimate the memory requirements
to group the class variable by calculating
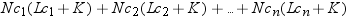
where
When you use the GROUPINTERNAL option in the CLASS statement,
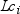 is simply the unformatted length of
is simply the unformatted length of 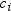 .
.
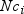
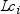
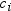
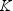 is simply the unformatted length of .
is simply the unformatted length of .
Each unique combination
of class variables, 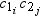 for a given type forms a level
in that type. See TYPES Statement. You can estimate the maximum potential
space requirements for all levels of a given type, when all combinations
actually exist in the data (a complete type), by calculating
for a given type forms a level
in that type. See TYPES Statement. You can estimate the maximum potential
space requirements for all levels of a given type, when all combinations
actually exist in the data (a complete type), by calculating
for a given type forms a level
in that type. See TYPES Statement. You can estimate the maximum potential
space requirements for all levels of a given type, when all combinations
actually exist in the data (a complete type), by calculating
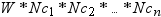
where
Clearly, the memory requirements of the levels overwhelm
the levels of the class variables. For this reason, PROC MEANS can
open one or more utility files and write the levels of one or more
types to disk. These types are either the primary types that PROC
MEANS built during the input data scan or the derived types.
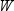
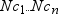
If PROC MEANS must write
partially complete primary types to disk while it processes input
data, then one or more merge passes can be required to combine type
levels in memory with the levels on disk. In addition, if you use
an order other than DATA for any class variable, then PROC MEANS groups
the completed types on disk. For this reason, the peak disk space
requirements can be more than twice the memory requirements for a
given type.
Processing on disk occurred during summarization.
Peak disk usage was approximately nnn
Mbytes.
Adjusting MEMSIZE or REALMEMSIZE may improve performance.When you specify class
variables in a CLASS statement, the amount of data-dependent memory
that PROC MEANS uses before it writes to a utility file is controlled
by the SAS system option REALMEMSIZE=. The value of REALMEMSIZE= indicates
the amount of real as opposed to virtual memory that SAS can expect
to allocate. PROC MEANS determines how much data-dependent memory
to use before writing to utility files by calculating the lesser of
these two values:
As an alternative, you
can use the PROC option SUMSIZE=. Like the PROC option SORTSIZE=,
SUMSIZE= sets the memory threshold where disk-based operations begin.
For best results, set SUMSIZE= to less than the amount of real memory
that is likely to be available for the task. For efficiency reasons,
PROC MEANS can internally round up the value of SUMSIZE=. SUMSIZE=
has no effect unless you specify class variables.
Operating Environment Information: The
REALMEMSIZE= SAS system option is not available in all operating environments.
For details, see the SAS Companion for your operating environment.
If PROC MEANS reports
that there is insufficient memory, then increase SUMSIZE= (or REALMEMSIZE=).
A SUMSIZE= (or REALMEMSIZE=) value that is greater than MEMSIZE= will
have no effect. Therefore, you might also need to increase MEMSIZE=.
If PROC MEANS reports insufficient disk space, then increase the
WORK space allocation. See the SAS documentation for your operating
environment for more information about how to adjust your computation
resource parameters.
Another way to enhance
performance is by carefully applying the TYPES or WAYS statement,
limiting the computations to only those combinations of class variables
that you are interested in. In particular, significant resource savings
can be achieved by not requesting the combination of all class variables.
In-Database Processing for PROC MEANS
When large data sets
are stored in an external database, the transfer of the data sets
to computers that run SAS can be impacted by performance, security,
and resource management issues. SAS in-database processing can greatly
reduce data transfer by having the database perform the initial data
aggregation.
Under the correct conditions,
PROC MEANS generates an SQL query based on the statements that are
used and the output statistics that are specified in the PROC step.
If class variables are specified, the procedure creates an SQL GROUP
BY clause that represents the n-way type. The result set that is created
when the aggregation query executes in the database is read by SAS
into the internal PROC MEANS data structure, and all subsequent types
are derived from the original n-way type to form the final analysis
results. When SAS format definitions have been deployed in the database,
formatting of class variables occurs in the database. If the SAS format
definitions have not been deployed in the database, the in-database
aggregation occurs on the raw values, and the relevant formats are
applied by SAS as the results' set is merged into the PROC MEANS internal
structures. Multi-label formatting is always done by SAS using the
initially aggregated result set that is returned by the database.
The CLASS, TYPES, WAYS, VAR, BY, FORMAT, and WHERE statements are
supported when PROC MEANS is processed inside the database. FREQ,
ID, IDMIN, IDMAX, and IDGROUPS are not supported. The following statistics
are supported for in-database processing: N, NMISS, MIN, MAX, RANGE,
SUM, SUMWGT, MEAN, CSS, USS, VAR, STD, STDERR, PRET, UCLM, LCLM, CLM,
and CV.
Weighting for in-database
processing is supported only for N, NMISS, MIN, MAX, RANGE, SUM, SUMWGT,
and MEAN.
The following statistics
are currently not supported for in-database processing: SKEW, KURT,
P1, P5, P10, P20, P25/Q1, P30, P40, P50/MEDIAN, P60, P70, P75/Q3,
P80, P90, P95, P99, and MODE.
The SQLGENERATION system
option or LIBNAME statement option controls whether and how in-database
procedures are run inside the database. By default, the in-database
procedures are run inside the database when possible. There are many
data set options that will prevent in-database processing: OBS=, FIRSTOBS=,
RENAME=, and DBCONDITION=. For a complete listing, refer to “In-Database
Procedures in Teradata” in SAS/ACCESS for Relational Databases: Reference.
In-database processing
can greatly reduce the volume of data transferred to the procedure
if there are no class variables (one row is returned) or if the selected
class variables have a small number of unique values. However, because
PROC MEANS loads the result set into its internal structures, the
memory requirements for the SAS process will be equivalent to what
would have been required without in-database processing. The CPU requirements
for the SAS process should be significantly reduced if the bulk of
the data summarization occurs inside the database. The real time required
for summarization should be significantly reduced because many database-process
queries are in parallel.