The SURVEYMEANS Procedure

After a probability sample is drawn and survey data are collected, researchers sometimes want to stratify the sample according to auxiliary information about the sampled population. This process is often called poststratification.
When poststratification is done properly, it can improve efficiency. It can also be used to adjust the sampling weights such that the marginal distribution of the sampling weights is in agreement with known auxiliary information from other resources, such as the census. The adjusted weight is often called the poststratification weight. It is quite common for researchers to use poststratification techniques in survey data analysis.
Poststratification is also used by epidemiologists, who frequently analyze health survey data. They often compute statistics based on a process called direct standardization, a form of poststratification. For example, certain diseases, such as cancer, are more common among older populations. Therefore, to compare the prevalence rates among geographic regions that are populated with different age groups, it is necessary to make adjustments according to such demographic categories and to compute relative prevalence rates of the diseases.
For more information about poststratification, see Fuller (2009); Lohr (2010); Wolter (2007); Rao, Yung, and Hidiroglou (2002).
After you provide the population controls for each poststratum that is defined by the poststratification variables, the SURVEYMEANS procedure creates the poststratification weights accordingly. Then the procedure computes statistics that you request by using poststratification weights.
You can save the poststratification weights in an OUTPSWGT= data to be used in subsequent analyses.
For a selected sample, let ![]() be the poststratum index; let
be the poststratum index; let ![]() be the population totals for each corresponding poststratum; and let
be the population totals for each corresponding poststratum; and let ![]() be a corresponding indicator variable for the poststratum p defined by
be a corresponding indicator variable for the poststratum p defined by
Denote the total sum of original weights in the sample for each poststratum as
Then the poststratification weight for the observation (h, i, j) is
The SURVEYMEANS procedure computes statistics by using the poststratification weights ![]() instead of the original weights
instead of the original weights ![]() .
.
The standard error and confidence intervals of computed statistics are based on the estimated variance, using either a replication method or the Taylor series method.
When you specify VARMETHOD=BRR or VARMETHOD=JACKKNIFE, PROC SURVEYMEANS computes the variance of a statistic by using replication methods, as described in the section Replication Methods for Variance Estimation. However, with poststratification, an extra step is needed to adjust the weights.
First, PROC SURVEYMEANS constructs a replicate and computes appropriate replicate weights for the replicate. Then, by using the poststratification control totals, the procedure adjusts these replicate weights in the same way as described previously for constructing the poststratification weights for the full sample. Finally, PROC SURVEYMEANS computes the estimate for a desired statistics by using the poststratification weights that are adjusted from the replicate weights in the current replicate. Then the final variance is estimated by the variability among replicate estimates, as described in the section Replication Methods for Variance Estimation.
When you specify VARMETHOD=TAYLOR, or by default when you do not specify the VARMETHOD= option, PROC SURVEYMEANS uses the Taylor series method to estimate the variances of requested statistics.
The sum and mean of variable Y under poststratification is
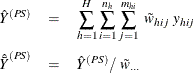
where
is the sum of the poststratification weights over all observations in the sample.
For each poststratum ![]() , let the mean of variable Y in each poststratum be
, let the mean of variable Y in each poststratum be
where ![]() is the total of the poststratification weights in poststratum p.
is the total of the poststratification weights in poststratum p.
For observation (h, i, j), assume that it belongs to the pth poststratum. Let
PROC SURVEYMEANS estimates the variance of ![]() as
as
where, if ![]() , then
, then
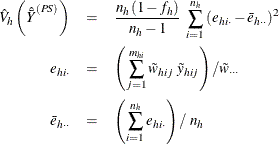
and if ![]() , then
, then
PROC SURVEYMEANS estimates the variance of ![]() as
as
For a domain D, let ![]() be the corresponding indicator variable:
be the corresponding indicator variable:
Let
The sum and mean of variable Y under poststratification in domain D are
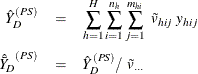
where
is the sum of the poststratification weights over all observations in the sample in domain D. For each poststratum ![]() , let the mean of variable Y and the mean of the domain indicator variable in each poststratum be
, let the mean of variable Y and the mean of the domain indicator variable in each poststratum be
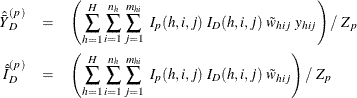
Assume that the observation (h, i, j) belongs to the pth poststratum. Let
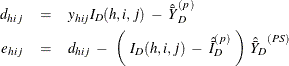
Then PROC SURVEYMEANS estimates the variance of domain sum ![]() as
as
where, if ![]() , then
, then
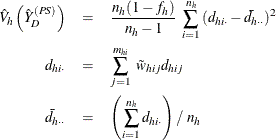
and if ![]() , then
, then
Then PROC SURVEYMEANS estimates the variance of domain mean ![]() as
as
where, if ![]() , then
, then
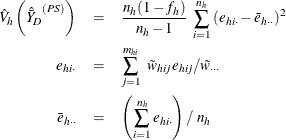
and if ![]() , then
, then
Suppose you want to calculate the ratio of variable Y to variable X. Let ![]() and
and ![]() be the values of variable X and variable Y, respectively, for observation (h, i, j).
be the values of variable X and variable Y, respectively, for observation (h, i, j).
The ratio of Y to X after poststratification is
where ![]() is the poststratification weight for observation
is the poststratification weight for observation ![]() .
.
Assume that the observation (h, i, j) belongs to the pth poststratum. Let
where ![]() and
and ![]() are the means of variable Y and variable X, respectively, in poststratum p.
are the means of variable Y and variable X, respectively, in poststratum p.
The variance of ![]() is estimated by
is estimated by
where, if ![]() , then
, then
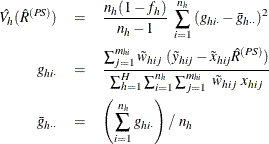
and if ![]() , then
, then
For a domain D, let ![]() be the corresponding indicator variable:
be the corresponding indicator variable:
Let
The ratio of variable Y to variable X in domain D after poststratification is estimated by
For each poststratum ![]() , let the mean of variable X and Y in each poststratum be
, let the mean of variable X and Y in each poststratum be
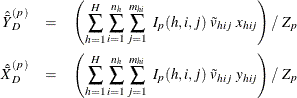
Assume that the observation (h, i, j) belongs to the pth poststratum. Let
Then PROC SURVEYMEANS estimates the variance of domain ratio ![]() after poststratification as
after poststratification as
where, if ![]() , then
, then
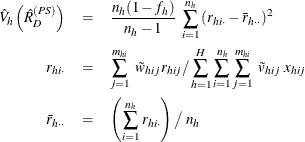
and if ![]() , then
, then