The TTEST Procedure

Define the following notation:

Observations at the first class level are assumed to be distributed as ![]() , and observations at the second class level are assumed to be distributed as
, and observations at the second class level are assumed to be distributed as ![]() , where
, where ![]() ,
, ![]() ,
, ![]() , and
, and ![]() are unknown.
are unknown.
The within-class-level mean estimates (![]() and
and ![]() ), standard deviation estimates (
), standard deviation estimates (![]() and
and ![]() ), standard errors (
), standard errors (![]() and
and ![]() ), and confidence limits for means and standard deviations are computed in the same way as for the one-sample design in the
section Normal Data (DIST=NORMAL).
), and confidence limits for means and standard deviations are computed in the same way as for the one-sample design in the
section Normal Data (DIST=NORMAL).
The mean difference ![]() is estimated by
is estimated by
Under the assumption of equal variances (![]() ), the pooled estimate of the common standard deviation is
), the pooled estimate of the common standard deviation is
![\[ s_ p = \left( \frac{(n_1-1)s_1^2+(n_2-1)s_2^2}{n_1+n_2-2} \right)^\frac {1}{2} \]](images/statug_ttest0086.png)
The pooled standard error (the estimated standard deviation of ![]() assuming equal variances) is
assuming equal variances) is
![\[ \mr {SE}_ p = s_ p \left( \frac{1}{\sum _{i=1}^{n^\star _1} f_{1i} w_{1i}} + \frac{1}{\sum _{i=1}^{n^\star _2} f_{2i} w_{2i}} \right)^\frac {1}{2} \]](images/statug_ttest0088.png)
The pooled ![]() confidence interval for the mean difference
confidence interval for the mean difference ![]() is
is
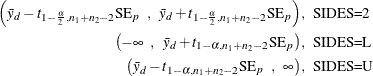
The t value for the pooled test is computed as
The p-value of the test is computed as
![\[ \mbox{\Mathtext{p}-value} = \left\{ \begin{array}{ll} P \left( t_ p^2 > F_{1-\alpha , 1, n_1+n_2-2} \right) \; \; , & \mbox{2-sided} \\ P \left( t_ p < t_{\alpha , n_1+n_2-2} \right) \; \; , & \mbox{lower 1-sided} \\ P \left( t_ p > t_{1-\alpha , n_1+n_2-2} \right) \; \; , & \mbox{upper 1-sided} \\ \end{array} \right. \]](images/statug_ttest0092.png)
Under the assumption of unequal variances (the Behrens-Fisher problem), the unpooled standard error is computed as
![\[ \mr {SE}_ u = \left( \frac{s^2_1}{\sum _{i=1}^{n^\star _1} f_{1i} w_{1i}} + \frac{s^2_2}{\sum _{i=1}^{n^\star _2} f_{2i} w_{2i}} \right)^\frac {1}{2} \]](images/statug_ttest0093.png)
Satterthwaite’s (1946) approximation for the degrees of freedom, extended to accommodate weights, is computed as
![\[ \mr {df}_ u = \frac{\mr {SE}^4_ u}{\frac{s^4_1}{(n_1-1)\left(\sum _{i=1}^{n^\star _1} f_{1i} w_{1i}\right)^2} + \frac{s^4_2}{(n_2-1)\left(\sum _{i=1}^{n^\star _2} f_{2i} w_{2i}\right)^2}} \]](images/statug_ttest0094.png)
The unpooled Satterthwaite ![]() confidence interval for the mean difference
confidence interval for the mean difference ![]() is
is
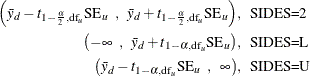
The t value for the unpooled Satterthwaite test is computed as
The p-value of the unpooled Satterthwaite test is computed as
![\[ \mbox{\Mathtext{p}-value} = \left\{ \begin{array}{ll} P \left( t_ u^2 > F_{1-\alpha , 1, \mr {df}_ u} \right) \; \; , & \mbox{2-sided} \\ P \left( t_ u < t_{\alpha , \mr {df}_ u} \right) \; \; , & \mbox{lower 1-sided} \\ P \left( t_ u > t_{1-\alpha , \mr {df}_ u} \right) \; \; , & \mbox{upper 1-sided} \\ \end{array} \right. \]](images/statug_ttest0097.png)
When the COCHRAN option is specified in the PROC TTEST statement, the Cochran and Cox (1950) approximation of the p-value of the ![]() statistic is the value of p such that
statistic is the value of p such that
![\[ t_ u = \frac{\left( \frac{s^2_1}{\sum _{i=1}^{n^\star _1} f_{1i} w_{1i}} \right) t_1 + \left( \frac{s^2_2}{\sum _{i=1}^{n^\star _2} f_{2i} w_{2i}} \right) t_2}{\left( \frac{s^2_1}{\sum _{i=1}^{n^\star _1} f_{1i} w_{1i}} \right) + \left( \frac{s^2_2}{\sum _{i=1}^{n^\star _2} f_{2i} w_{2i}} \right)} \]](images/statug_ttest0099.png)
where ![]() and
and ![]() are the critical values of the t distribution corresponding to a significance level of p and sample sizes of
are the critical values of the t distribution corresponding to a significance level of p and sample sizes of ![]() and
and ![]() , respectively. The number of degrees of freedom is undefined when
, respectively. The number of degrees of freedom is undefined when ![]() . In general, the Cochran and Cox test tends to be conservative (Lee and Gurland, 1975).
. In general, the Cochran and Cox test tends to be conservative (Lee and Gurland, 1975).
The ![]() CI=EQUAL and CI=UMPU confidence intervals for the common population standard deviation
CI=EQUAL and CI=UMPU confidence intervals for the common population standard deviation ![]() assuming equal variances are computed as discussed in the section Normal Data (DIST=NORMAL) for the one-sample design, except replacing
assuming equal variances are computed as discussed in the section Normal Data (DIST=NORMAL) for the one-sample design, except replacing ![]() by
by ![]() and
and ![]() by
by ![]() .
.
The folded form of the F statistic, ![]() , tests the hypothesis that the variances are equal (Steel and Torrie, 1980), where
, tests the hypothesis that the variances are equal (Steel and Torrie, 1980), where
A test of ![]() is a two-tailed F test because you do not specify which variance you expect to be larger. The p-value gives the probability of a greater F value under the null hypothesis that
is a two-tailed F test because you do not specify which variance you expect to be larger. The p-value gives the probability of a greater F value under the null hypothesis that ![]() . Note that this test is not very robust to violations of the assumption that the data are normally distributed, and thus
it is not recommended without confidence in the normality assumption.
. Note that this test is not very robust to violations of the assumption that the data are normally distributed, and thus
it is not recommended without confidence in the normality assumption.
The DIST=LOGNORMAL analysis is handled by log-transforming the data and null value, performing a DIST=NORMAL analysis, and then transforming the results back to the original scale. See the section Normal Data (DIST=NORMAL) for the one-sample design for details on how the DIST=NORMAL computations for means and standard deviations are transformed into the DIST=LOGNORMAL results for geometric means and CVs. As mentioned in the section Coefficient of Variation, the assumption of equal CVs on the lognormal scale is analogous to the assumption of equal variances on the normal scale.
The distributional assumptions, equality of variances test, and within-class-level mean estimates (![]() and
and ![]() ), standard deviation estimates (
), standard deviation estimates (![]() and
and ![]() ), standard errors (
), standard errors (![]() and
and ![]() ), and confidence limits for means and standard deviations are the same as in the section Normal Difference (DIST=NORMAL TEST=DIFF) for the two-independent-sample design.
), and confidence limits for means and standard deviations are the same as in the section Normal Difference (DIST=NORMAL TEST=DIFF) for the two-independent-sample design.
The mean ratio ![]() is estimated by
is estimated by
No estimates or confidence intervals for the ratio of standard deviations are computed.
Under the assumption of equal variances (![]() ), the pooled confidence interval for the mean ratio is the Fieller (1954) confidence interval, extended to accommodate weights. Let
), the pooled confidence interval for the mean ratio is the Fieller (1954) confidence interval, extended to accommodate weights. Let
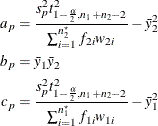
where ![]() is the pooled standard deviation defined in the section Normal Difference (DIST=NORMAL TEST=DIFF) for the two-independent-sample design. If
is the pooled standard deviation defined in the section Normal Difference (DIST=NORMAL TEST=DIFF) for the two-independent-sample design. If ![]() (which occurs when
(which occurs when ![]() is too close to zero), then the pooled two-sided
is too close to zero), then the pooled two-sided ![]() Fieller confidence interval for
Fieller confidence interval for ![]() does not exist. If
does not exist. If ![]() , then the interval is
, then the interval is
![\[ \left( -\frac{b_ p}{a_ p} + \frac{\left( b_ p^2 - a_ p c_ p \right)^\frac {1}{2}}{a_ p} \; \; , -\frac{b_ p}{a_ p} - \frac{\left( b_ p^2 - a_ p c_ p \right)^\frac {1}{2}}{a_ p} \; \; \right) \]](images/statug_ttest0117.png)
For the one-sided intervals, let
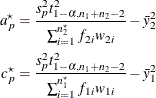
which differ from ![]() and
and ![]() only in the use of
only in the use of ![]() in place of
in place of ![]() . If
. If ![]() , then the pooled one-sided
, then the pooled one-sided ![]() Fieller confidence intervals for
Fieller confidence intervals for ![]() do not exist. If
do not exist. If ![]() , then the intervals are
, then the intervals are
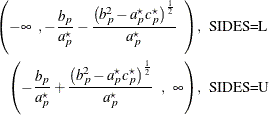
The pooled t test assuming equal variances is the Sasabuchi (1988a, 1988b) test. The hypothesis ![]() is rewritten as
is rewritten as ![]() , and the pooled t test in the section Normal Difference (DIST=NORMAL TEST=DIFF) for the two-independent-sample design is conducted on the original
, and the pooled t test in the section Normal Difference (DIST=NORMAL TEST=DIFF) for the two-independent-sample design is conducted on the original ![]() values (
values (![]() ) and transformed values of
) and transformed values of ![]()
with a null difference of 0. The t value for the Sasabuchi pooled test is computed as
![\[ t_ p = \frac{\bar{y}_1 - \mu _0 \bar{y}_2}{s_ p \left( \frac{1}{\sum _{i=1}^{n^\star _1} f_{1i} w_{1i}} + \frac{\mu _0^2}{\sum _{i=1}^{n^\star _2} f_{2i} w_{2i}} \right)^\frac {1}{2}} \]](images/statug_ttest0130.png)
The p-value of the test is computed as
Under the assumption of unequal variances, the unpooled Satterthwaite-based confidence interval for the mean ratio ![]() is computed according to the method in Dilba, Schaarschmidt, and Hothorn (2006), extended to accommodate weights. The degrees of freedom are computed as
is computed according to the method in Dilba, Schaarschmidt, and Hothorn (2006), extended to accommodate weights. The degrees of freedom are computed as
![\[ \mr {df}_ u = \frac{\left( \frac{s^2_1}{\sum _{i=1}^{n^\star _1} f_{1i} w_{1i}} + \frac{\hat{\mu }_ r^2 s^2_2}{\sum _{i=1}^{n^\star _2} f_{2i} w_{2i}} \right)^2}{\frac{s^4_1}{(n_1-1)\left(\sum _{i=1}^{n^\star _1} f_{1i} w_{1i}\right)^2} + \frac{\hat{\mu }_ r^4 s^4_2}{(n_2-1)\left(\sum _{i=1}^{n^\star _2} f_{2i} w_{2i}\right)^2}} \]](images/statug_ttest0131.png)
Note that the estimate ![]() is used in
is used in ![]() . Let
. Let
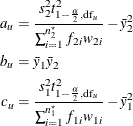
where ![]() and
and ![]() are the within-class-level standard deviations defined in the section Normal Difference (DIST=NORMAL TEST=DIFF) for the two-independent-sample design. If
are the within-class-level standard deviations defined in the section Normal Difference (DIST=NORMAL TEST=DIFF) for the two-independent-sample design. If ![]() (which occurs when
(which occurs when ![]() is too close to zero), then the unpooled Satterthwaite-based two-sided
is too close to zero), then the unpooled Satterthwaite-based two-sided ![]() confidence interval for
confidence interval for ![]() does not exist. If
does not exist. If ![]() , then the interval is
, then the interval is
![\[ \left( -\frac{b_ u}{a_ u} + \frac{\left( b_ u^2 - a_ u c_ u \right)^\frac {1}{2}}{a_ u} \; \; , -\frac{b_ u}{a_ u} - \frac{\left( b_ u^2 - a_ u c_ u \right)^\frac {1}{2}}{a_ u} \; \; \right) \]](images/statug_ttest0137.png)
The t test assuming unequal variances is the test derived in Tamhane and Logan (2004). The hypothesis ![]() is rewritten as
is rewritten as ![]() , and the Satterthwaite t test in the section Normal Difference (DIST=NORMAL TEST=DIFF) for the two-independent-sample design is conducted on the original
, and the Satterthwaite t test in the section Normal Difference (DIST=NORMAL TEST=DIFF) for the two-independent-sample design is conducted on the original ![]() values (
values (![]() ) and transformed values of
) and transformed values of ![]()
with a null difference of 0. The degrees of freedom used in the unpooled t test differs from the ![]() used in the unpooled confidence interval. The mean ratio
used in the unpooled confidence interval. The mean ratio ![]() under the null hypothesis is used in place of the estimate
under the null hypothesis is used in place of the estimate ![]() :
:
![\[ \mr {df}_ u^\star = \frac{\left( \frac{s^2_1}{\sum _{i=1}^{n^\star _1} f_{1i} w_{1i}} + \frac{\mu _0^2 s^2_2}{\sum _{i=1}^{n^\star _2} f_{2i} w_{2i}} \right)^2}{\frac{s^4_1}{(n_1-1)\left(\sum _{i=1}^{n^\star _1} f_{1i} w_{1i}\right)^2} + \frac{\mu _0^4 s^4_2}{(n_2-1)\left(\sum _{i=1}^{n^\star _2} f_{2i} w_{2i}\right)^2}} \]](images/statug_ttest0139.png)
The t value for the Satterthwaite-based unpooled test is computed as
![\[ t_ u = \frac{\bar{y}_1 - \mu _0 \bar{y}_2}{\left( \frac{s^2_1}{\sum _{i=1}^{n^\star _1} f_{1i} w_{1i}} + \frac{\mu _0^2 s^2_2}{\sum _{i=1}^{n^\star _2} f_{2i} w_{2i}} \right)^\frac {1}{2}} \]](images/statug_ttest0140.png)
The p-value of the test is computed as
![\[ \mbox{\Mathtext{p}-value} = \left\{ \begin{array}{ll} P \left( t_ u^2 > F_{1-\alpha , 1, \mr {df}_ u^\star } \right) \; \; , & \mbox{2-sided} \\ P \left( t_ u < t_{\alpha , \mr {df}_ u^\star } \right) \; \; , & \mbox{lower 1-sided} \\ P \left( t_ u > t_{1-\alpha , \mr {df}_ u^\star } \right) \; \; , & \mbox{upper 1-sided} \\ \end{array} \right. \]](images/statug_ttest0141.png)