The TIMEDATA Procedure
- Overview
- Getting Started
-
Syntax

-
DetailsAccumulationMissing Value InterpretationTime Series TransformationTime Series DifferencingSummary StatisticsProgramming StatementsPredefined SymbolsAuxiliary Data SetsData Set OutputOUT= Data SetOUTARRAY= Data SetOUTPROCINFO= Data SetOUTSCALAR= Data SetOUTSUM= Data Set_STATUS_ Variable ValuesPrinted OutputODS Table NamesODS Graphics Names
-
Examples
- References
Auxiliary data set support enables the TIMEDATA procedure to use auxiliary data sets to contribute input variables to the run of the procedure step. This functionality creates a virtual data source that enables some of the input variables to physically reside in different data sets with some defined in the primary data set defined by the DATA= option and others defined in the the data sets that are specified by one or more AUXDATA= options. For example, this functionality enables sharing of common time series data across multiple projects.
Furthermore, auxiliary data set support enables more than the simple separation of shared data. It also facilitates the elimination of redundancy in these auxiliary data sources by performing partial matching on BY-group qualification. Duplication of time series for the full BY-group hierarchy is no longer required for the auxiliary data sets.
Finally, this functionality permits more than one auxiliary data source to be used concurrently to materialize the virtual time series vectors across a given BY-group hierarchy. So variables that have naturally different levels of BY-group qualification can be isolated into separate data sets and supplied with separate AUXDATA= options to optimize data management and performance.
When used, this option declares the presence of an auxiliary data set to optionally provide time series variables to satisfy various declaration statements in the respective procedure steps.
There are two classes of time series data set sources:
-
a primary data set from the DATA=
DataSetoption -
auxiliary data sources from AUXDATA=
DataSetoptions
You can specify zero or more AUXDATA= options in the PROC TIMEDATA statement. Each AUXDATA= option establishes an auxiliary data set source to supply variables declared in subsequent statements that comprise the procedure step.
Variables referenced in the PROC TIMEDATA invocation fall into three classes:
-
those that must be physically present in the primary data set
-
those that must be physically present in each auxiliary data set
-
those that can reside in either the primary or an auxiliary data set
If you specify an ID variable for PROC TIMEDATA, it must be present in the primary data set and all of the auxiliary data sets that you specify. Variables that you specify in the BY statement must be present in the primary data set. A leftmost subset of those BY variables can be present in each of the auxiliary data sets that you specify, and it is not required that all auxiliary data sets contain the same subset. Partial BY group matching is performed for each auxiliary data set independent of the others.
The time series variables that you specify in VAR statements can be resolved from either the primary data set or an auxiliary data set. Variable resolution proceeds in reverse order from the last AUXDATA= option in the PROC TIMEDATA statement to the first. If the variable in question is not found in any of those, the variable must be present in the primary data set for the procedure step to be successful.
All BY statement variables must be physically present in the primary data set. However, it is not necessary to have the BY variables present in any of the auxiliary data sets. All, some, or none of the BY variables can be present in any auxiliary data set, as your requirements dictate. Partial BY-group matching is performed between the primary data set and the auxiliary data sets based on the number of BY statement variables that are present in the respective auxiliary data sets.
For example, suppose you have a hierarchy of (REGION, PRODUCT) in the primary data set, which holds the time series variables for monthly sales metrics. Suppose you have an auxiliary data set with time series qualified by REGION for pertinent explanatory variables and another with time series for other explanatory variables to be applied across all (REGION, PRODUCT) groupings of the primary data set. In this scenario, each (REGION, PRODUCT) group in the primary data set seeks a match with a corresponding REGION from the first auxiliary data set to materialize the time series for its variables, but no matching is performed on the second auxiliary data set to materialize the time series for its variables. So if ('SOUTH','EDSEL') is a BY group from the primary data set, the 'SOUTH' BY group series from the first auxiliary data set are used, and the series from the second auxiliary data set are supplied without qualification. If the next primary BY group is ('SOUTH', 'HUDSON'), then the 'SOUTH' BY group is again used to supply the time series from the first auxiliary data set, and the unqualified series are supplied from the second auxiliary data set. So on it goes, each auxiliary data set performing a partial match on the BY variables it holds within the BY group from the primary data set.
The series from each BY group of the primary data set defines a reference time span for the auxiliary data sets. Only the intersection of the time interval for each auxiliary series with the reference span is materialized. Head or tail missing values are inserted into the auxiliary series for start or stop times that lie inside the reference span. More generally, missing value semantics apply to the head and tail regions that require filling to materialize the full reference time span.
With time series materialized from a single primary data set, there is no latitude for different time ID ranges between the different variables because each observation read contains not only the time ID but also the associated values for all of the variables. With some series materialized from the primary data set and some materialized from auxiliary data sets, the possibility exists for the reference time span to have an arbitrary intersection with the time span of the corresponding series from the auxiliary sources. The intent is to materialize the portion of the auxiliary series time span that intersects with the reference time span and to handle head and tail shortages via missing value semantics as needed.
For the previous usage scenario with a primary data set and two auxiliary data sets, when data is read over a sequence of primary BY groups it might be necessary to materialize various spans of the auxiliary series with appropriate missing value semantics applied as needed to resolve head and tail shortages even though the actual time series contributed from the auxiliary data sets does not physically change. The following discussion breaks this down into several cases depending on intersection possibilities between the reference time span and the auxiliary time span.
Legend:
-
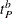 denotes the begin time ID of the primary (DATA=) series.
denotes the begin time ID of the primary (DATA=) series.
-
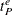 denotes the end time ID of the primary (DATA=) series.
denotes the end time ID of the primary (DATA=) series.
-
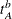 denotes the begin time ID of the AUXDATA series.
denotes the begin time ID of the AUXDATA series.
-
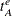 denotes the end time ID of the AUXDATA series.
denotes the end time ID of the AUXDATA series.
-
![$[t_ P^ b,t_ P^ e]$](images/etsug_timedata0016.png) denotes the time span for the primary (DATA=) series (also known as the reference time span).
denotes the time span for the primary (DATA=) series (also known as the reference time span).
-
![$[t_ A^ b,t_ A^ e]$](images/etsug_timedata0017.png) denotes the time span for the AUXDATA series.
denotes the time span for the AUXDATA series.
 |
Here ![]() . The auxiliary time span includes the reference span as a subset. Values in the AUXDATA series to the left of
. The auxiliary time span includes the reference span as a subset. Values in the AUXDATA series to the left of ![]() and values to the right of
and values to the right of ![]() are truncated from the AUXDATA series that is materialized in connection with the primary series.
are truncated from the AUXDATA series that is materialized in connection with the primary series.
 |
Here ![]() . The reference time span leads the auxiliary time span with a non-empty intersection. AUXDATA series values in
. The reference time span leads the auxiliary time span with a non-empty intersection. AUXDATA series values in ![]() are materialized with missing value semantics. AUXDATA series values in
are materialized with missing value semantics. AUXDATA series values in ![]() are materialized as actual subject to missing value semantics.
are materialized as actual subject to missing value semantics.
 |
Here ![]() . The reference time span lags the auxiliary time span with a non-empty intersection. AUXDATA series values in
. The reference time span lags the auxiliary time span with a non-empty intersection. AUXDATA series values in ![]() are materialized as actual subject to missing value semantics. AUXDATA series values in
are materialized as actual subject to missing value semantics. AUXDATA series values in ![]() are materialized with missing value semantics.
are materialized with missing value semantics.
 |
Here ![]() . The auxiliary time span is a subset of the reference time span. AUXDATA series values in
. The auxiliary time span is a subset of the reference time span. AUXDATA series values in ![]() and values in
and values in ![]() are materialized with missing value semantics. AUXDATA series values in
are materialized with missing value semantics. AUXDATA series values in ![]() are materialized as actual subject to missing value semantics.
are materialized as actual subject to missing value semantics.
