MODIFY Statement
| Valid in: | DATA step |
| Category: | File-handling |
| Type: | Executable |
| Restriction: | Cannot modify the descriptor portion of a SAS data set, such as adding a variable |
| Note: | If you modify a password-protected data set, specify the password with the appropriate data set option (ALTER= or PW=) within the MODIFY statement, and not in the DATA statement. |
| CAUTION: |
Damage
to the SAS data set can occur if the system terminates abnormally
during a DATA step that contains the MODIFY statement.
|
Syntax
Form 1:
<NOBS=variable> <END=variable>
<UPDATEMODE=MISSINGCHECK | NOMISSINGCHECK>;
BY by-variable;
Form 2:
Form 3:
Form 4:
Arguments
- master-data-set
-
specifies the SAS data set that you want to modify.Restrictions:This data set must also appear in the DATA statement.
For sequential and matching access, the master data set can be a SAS data file, a
SAS/ACCESS view, an SQL view, or a DBMS engine for the LIBNAME statement. It cannot be a DATA step view or a pass-through view.For random access using POINT=, the master data set must be a SAS data file or an SQL view that references a SAS data file.
For direct access using KEY=, the master data set can be a SAS data file or the DBMS engine for the LIBNAME statement. If it is a SAS file, it must be indexed and the index name must be specified on the KEY= option.
For a DBMS, the KEY= is set to the keyword DBKEY and the column names to use as an index must be specified on the DBKEY= data set option. These column names are used in constructing a WHERE expression that is passed to the DBMS.
Tip:Instead of using a data set name, you can specify the physical pathname to the file, using syntax that your operating system understands. The pathname must be enclosed in single or double quotation marks.
- (data-set-options)
-
specifies one or more SAS data set options in parentheses after a SAS data set name.Note:The data set options specify actions that SAS is to take when it reads observations into the DATA step for processing. For a list of data set options, see the SAS Data Set Options: ReferenceTip:Data set options that apply to a data set list apply to all of the data sets in the list.
- transaction-data-set
-
specifies the SAS data set that provides the values for matching access. These values are the values that you want to use to update the master data set.Restriction:Specify this data set only when the DATA step contains a BY statement.Tip:Instead of using a data set name, you can specify the physical pathname to the file, using syntax that your operating system understands. The pathname must be enclosed in single or double quotation marks.
- END=variable
-
creates and names a temporary variable that contains an end-of-file indicator.Restriction:Do not use this argument in the same MODIFY statement with the POINT= argument. POINT= indicates that MODIFY uses random access. The value of the END= variable is never set to 1 for random access.Notes:The variable, which is initialized to zero, is set to 1 when the MODIFY statement reads the last observation of the data set being modified (for sequential access ) or the last observation of the transaction data set (for matching access ). It is also set to 1 when MODIFY cannot find a match for a KEY= value (random access ).
This variable is not added to any data set.
- KEY=index
-
specifies a simple or composite index of the SAS data file that is being modified. The KEY= argument retrieves observations from that SAS data file based on index values that are supplied by like-named variables in another source of information.Default:If the KEY= value is not found, the automatic variable _ERROR_ is set to 1, and the automatic variable _IORC_ receives the value corresponding to the SYSRC autocall macro's mnemonic _DSENOM. See Automatic Variable _IORC_ and the SYSRC Autocall Macro.Restriction:KEY= processing is different for
SAS/ACCESS engines. See theSAS/ACCESS documentation for more information.Tips:Examples of sources for index values include a separate SAS data set named in a SET statement and an external file that is read by an INPUT statement.If duplicates exist in the master file, only the first occurrence is updated unless you use a DO-LOOP to execute a SET statement for the data set that is listed on the KEY=option for all duplicates in the master data set.
If duplicates exist in the transaction data set, and they are consecutive, use the UNIQUE option to force the search for a match in the master data set to begin at the top of the index. Write an accumulation statement to add each duplicate transaction to the observation in master. Without the UNIQUE option, only the first duplicate transaction observation updates the master.
If the duplicates in the transaction data set are not consecutive, the search begins at the beginning of the index each time, so that each duplicate is applied to the master. Write an accumulation statement to add each duplicate to the master.
See:UNIQUE
- NOBS=variable
-
creates and names a temporary variable whose value is usually the total number of observations in the input data set. For certain SAS views, SAS cannot determine the number of observations. In these cases, SAS sets the value of the NOBS= variable to the largest positive integer value available in the operating environment.Note:At compilation time, SAS reads the descriptor portion of the data set and assigns the value of the NOBS= variable automatically. Thus, you can refer to the NOBS= variable before the MODIFY statement. The variable is available in the DATA step but is not added to the new data set.Tip:The NOBS= and POINT= options are independent of each other.
- POINT=variable
-
reads SAS data sets using random (direct) access by observation number. variable names a variable whose value is the number of the observation to read. The POINT= variable is available anywhere in the DATA step, but it is not added to any SAS data set.Restrictions:You cannot use the POINT= option with any of the following:
You can use POINT= with compressed data sets only if the data set was created with the POINTOBS= data set option set to YES, the default value.
You can use the random access method on compressed files only with SAS version 7 and beyond.
Requirements:When using the POINT= argument, include one or both of the following programming constructs:Because POINT= reads only the specified observations, SAS cannot detect an end-of-file condition as it would if the file were being read sequentially. Because detecting an end-of-file condition terminates a DATA step automatically, failure to substitute another means of terminating the DATA step when you use POINT= can cause the DATA step to go into a continuous loop.
Tip: If the POINT= value does not match an observation number, SAS sets the automatic variable _ERROR_ to 1.
- UNIQUE
-
causes a KEY= search always to begin at the top of the index for the data file being modified.Restriction:UNIQUE can appear only with the KEY= option.Tip:Use UNIQUE when there are consecutive duplicate KEY= values in the transaction data set, so that the search for a match in the master data set begins at the top of the index file for each duplicate transaction. You must include an accumulation statement or the duplicate values overwrite each other causing only the last transaction value to be the result in the master observation.Example:Handling Duplicate Index Values
- UPDATEMODE=MISSINGCHECK | NOMISSINGCHECK
-
specifies whether missing variable values in a transaction data set are to be allowed to replace existing variable values in a master data set.
- MISSINGCHECK
-
prevents missing variable values in a transaction data set from replacing values in a master data set.
- NOMISSINGCHECK
-
allows missing variable values in a transaction data set to replace values in a master data set by preventing the check from being performed.
Default:MISSINGCHECKRequirement:The UPDATEMODE argument must be accompanied by a BY statement that specifies the variables by which observations are matched.Tip:However, special missing values are the exception and they replace values in the master data set even when MISSINGCHECK is in effect.
Details
Matching Access (Form 1)
Duplicate BY Values (Form 1)
-
If duplicates exist in the transaction data set, the duplicates are applied one on top of another unless you write an accumulation statement to add all of them to the master observation. Without the accumulation statement, the values in the duplicates overwrite each other so that only the value in the last transaction is the result in the master observation.
Direct Access by Indexed Values (Form 2)
Duplicate Index Values (Form 2)
-
If there are duplicate, nonconsecutive values in the like-named variable in the data source, MODIFY applies each transaction cumulatively to the first observation in the master data set whose index value matches the values from the data source. Therefore, only the value in the last duplicate transaction is the result in the master observation unless you write an accumulation statement to accumulate each duplicate transaction value in the master observation.
-
If there are duplicate, consecutive values in the variable in the data source, the values from the first observation in the data source are applied to the master data set, but the DATA step terminates with an error when it tries to locate an observation in the master data set for the second duplicate from the data source. To avoid this error, use the UNIQUE option in the MODIFY statement. The UNIQUE option causes SAS to return to the top of the master data set before retrieving a match for the index value. You must write an accumulation statement to accumulate the values from all the duplicates. If you do not, only the last one applied is the result in the master observation.Handling Duplicate Index Values shows how to handle duplicate index values.
Direct (Random) Access by Observation Number (Form 3)
Preparing Your Data Sets Before Using MODIFY
Automatic Variable _IORC_ and the SYSRC Autocall Macro
Writing Observations When MODIFY Is Used in a DATA Step
-
The OUTPUT, REPLACE, and REMOVE statements are independent of each other. You can code multiple OUTPUT, REPLACE, and REMOVE statements to apply to one observation. However, once an OUTPUT, REPLACE, or REMOVE statement executes, the MODIFY statement must execute again before the next REPLACE or REMOVE statement executes.You can use OUTPUT and REPLACE in the following example of conditional logic because only one of the REPLACE or OUTPUT statements executes per observation:
data master; modify master trans; by key; if _iorc_=0 then replace; else output; run;But you should not use multiple REPLACE operations on the same observation as in this example:data master; modify master; x=1; replace; replace; run;
Missing Values and the MODIFY Statement
A through Z for
the transaction data set, SAS updates numeric variables in the master
data set to that value.
Using MODIFY in a SAS/SHARE Environment
Comparisons
-
When you use a MERGE, SET, or UPDATE statement in a DATA step, SAS creates a new SAS data set. The data set descriptor of the new copy can be different from the old one (variables added or deleted, labels changed, and so on). When you use a MODIFY statement in a DATA step, however, SAS does not create a new copy of the data set. As a result, the data set descriptor cannot change.
-
If you use a BY statement with a MODIFY statement, MODIFY works much like the UPDATE statement, except that
-
neither the master data set nor the transaction data set needs to be sorted or indexed. (The BY statement that is used with MODIFY triggers dynamic WHERE processing.)Note: Dynamic WHERE processing can be costly if the MODIFY statement modifies a SAS data set that is not in sorted order or has not been indexed. Having the master data set in sorted order or indexed and having the transaction data set in sorted order reduces processing overhead, especially for large files.
-
both the master data set and the transaction data set can have observations with duplicate values of the BY variables. MODIFY treats the duplicates as described in Duplicate BY Values (Form 1).
-
Examples
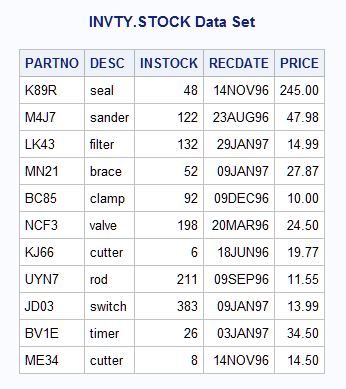
Example 1: Input Data Set for Examples
libname invty 'SAS-library';data invty.stock(index=(partno));
input PARTNO $ DESC $ INSTOCK @17
RECDATE date7. @25 PRICE;
format recdate date7.;
datalines;
K89R seal 34 27jul95 245.00
M4J7 sander 98 20jun95 45.88
LK43 filter 121 19may96 10.99
MN21 brace 43 10aug96 27.87
BC85 clamp 80 16aug96 9.55
NCF3 valve 198 20mar96 24.50
KJ66 cutter 6 18jun96 19.77
UYN7 rod 211 09sep96 11.55
JD03 switch 383 09jan97 13.99
BV1E timer 26 03jan97 34.50
;Example 2: Modifying All Observations
data invty.stock; modify invty.stock; recdate=today(); run; proc print data=invty.stock noobs; title 'INVTY.STOCK'; run;
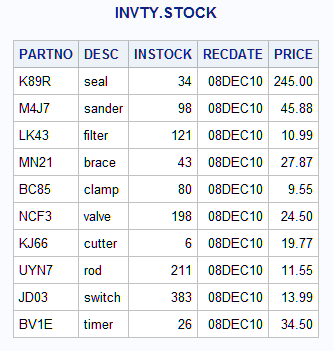
Example 3: Modifying Observations Using a Transaction Data Set
data addinv; input PARTNO $ NWSTOCK; datalines; K89R 55 M4J7 21 LK43 43 MN21 73 BC85 57 NCF3 90 KJ66 2 UYN7 108 JD03 55 BV1E 27 ;
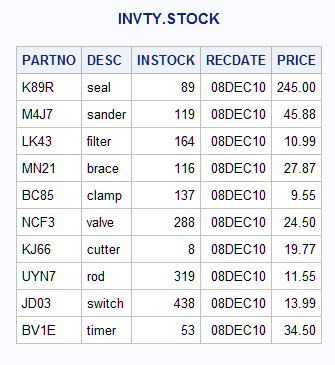
Example 4: Modifying Observations Located by Observation Number
data newp; input TOOL_OBS NEWP; datalines; 1 251.00 2 49.33 3 12.32 4 30.00 5 15.00 6 25.75 7 22.00 8 14.00 9 14.32 10 35.00 ;
libname invty 'SAS-library';data invty.stock;
set newp;
modify invty.stock point=tool_obs
nobs=max_obs;
if _error_=1 then
do;
put 'ERROR occurred for TOOL_OBS=' tool_obs /
'during DATA step iteration' _n_ /
'TOOL_OBS value might be out of range.';
_error_=0;
stop;
end;
PRICE=newp;
RECDATE=today();
run;proc print data=invty.stock noobs; title 'INVTY.STOCK'; run;
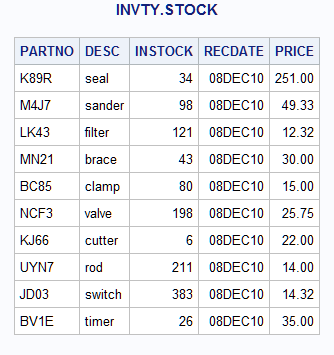
Example 5: Modifying Observations Located by an Index
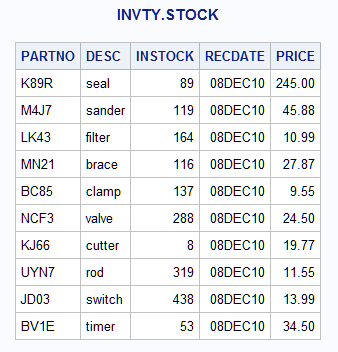
Example 6: Handling Duplicate Index Values
data newinv; input PARTNO $ NWSTOCK; datalines; K89R 55 M4J7 21 M4J7 26 LK43 43 MN21 73 BC85 57 NCF3 90 KJ66 2 UYN7 108 JD03 55 BV1E 27 ;
M4J7 in
NEWINV:libname invty 'SAS-library';/* This DATA step terminates with an error! */ data invty.stock; set newinv; modify invty.stock key=partno; INSTOCK=instock+nwstock; RECDATE=today(); run;
ERROR: No matching observation was found in MASTER data set. PARTNO=M4J7 NWSTOCK=26 DESC=sander INSTOCK=166 RECDATE=08DEC10 PRICE=45.88 _ERROR_=1 _IORC_=1230015 _N_=3 NOTE: The SAS System stopped processing this step because of errors. NOTE: There were 3 observations read from the data set WORK.NEWINV. NOTE: The data set INVTY.STOCK has been updated. There were 2 observations rewritten, 0 observations added and 0 observations deleted.
M4J7 in the
MASTER data set for each occurrence of M4J7 in
the SET data set. The updated result for M4J7 in
the output shows that both values of NWSTOCK from NEWINV for M4J7 are
added to the value of INSTOCK for M4J7 in
INVTY.STOCK. An accumulation statement sums the values; without it,
only the value of the last instance of M4J7 would
be the result in INVTY.STOCK.
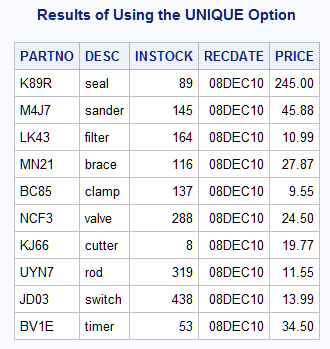
Example 7: Controlling I/O
data newship;
input PARTNO $ DESC $ NWSTOCK @17
SHPDATE date7. @25 NWPRICE;
datalines;
K89R seal 14 14nov96 245.00
M4J7 sander 24 23aug96 47.98
LK43 filter 11 29jan97 14.99
MN21 brace 9 09jan97 27.87
BC85 clamp 12 09dec96 10.00
ME34 cutter 8 14nov96 14.50
;data invty.stock;
set newship;
modify invty.stock key=partno;
select (_iorc_);
when (%sysrc(_sok)) do;
INSTOCK=instock+nwstock;
RECDATE=shpdate;
PRICE=nwprice;
replace;
end;
when (%sysrc(_dsenom)) do;
INSTOCK=nwstock;
RECDATE=shpdate;
PRICE=nwprice;
output;
_error_=0;
end;
otherwise do;
put
'An unexpected I/O error has occurred.'/
'Check your data and your program';
_error_=0;
stop;
end;
end;
run;