INPUT Statement
Describes the arrangement of values in the input
data record and assigns input values to the corresponding SAS variables.
| Valid in: | DATA step |
| Category: | File-handling |
| Type: | Executable |
Syntax
Without Arguments
For an example, see
Using a Null INPUT Statement.
Arguments
- specification(s)
-
can include
- (variable-list)
-
specifies a list of variables that are assigned input values.Requirement:The (variable-list) is followed by an (informat-list).
- $
-
specifies to store the variable value as a character value rather than as a numeric value.Tip:If the variable is previously defined as character, $ is not required.
- column-specifications
-
specifies the columns of the input record that contain the value to read.Tip:Informats are ignored. Only standard character and numeric data can be read correctly with this method.See:Column Input
- format-modifier
-
allows modified list input or controls the amount of information that is reported in the SAS log when an error in an input value occurs.Tip:Use modified list input to read data that cannot be read with simple list input.
- informat.
-
specifies an informat to use to read the variable value.Tip:You can use modified list input to read data with informats. Modified list input is useful when the data require informats but cannot be read with formatted input because the values are not aligned in columns.Example:Using Informat Lists
- @
-
holds an input record for the execution of the next INPUT statement within the same iteration of the DATA step. This line-hold specifier is called trailing @.Restriction:The trailing @ must be the last item in the INPUT statement.Tip:The trailing @ prevents the next INPUT statement from automatically releasing the current input record and reading the next record into the input buffer. It is useful when you need to read from a record multiple times.
- @@
-
holds the input record for the execution of the next INPUT statement across iterations of the DATA step. This line-hold specifier is called double trailing @.Restriction:The double trailing @ must be the last item in the INPUT statement.Tip:The double trailing @ is useful when each input line contains values for several observations, or when a record needs to be reread on the next iteration of the DATA step.
Column Pointer Controls
- @n
-
moves the pointer to column n.Range:a positive integerTip:If n is not an integer, SAS truncates the decimal value and uses only the integer value. If n is zero or negative, the pointer moves to column 1.Example:@15 moves the pointer to column 15:
input @15 name $10.;
Example:Moving the Pointer Backward
- @numeric-variable
-
moves the pointer to the column given by the value of numeric-variable.Range:a positive integerTip:If numeric-variable is not an integer, SAS truncates the decimal value and only uses the integer value. If numeric-variable is zero or negative, the pointer moves to column 1.Example:The value of the variable A moves the pointer to column 15:
a=15; input @a name $10.;
- @(expression)
-
moves the pointer to the column that is given by the value of expression.Restriction:Expression must result in a positive integer.Tip:If the value of expression is not an integer, SAS truncates the decimal value and only uses the integer value. If it is zero or negative, the pointer moves to column 1.Example:The result of the expression moves the pointer to column 15:
b=5; input @(b*3) name $10.;
- @'character-string'
-
locates the specified series of characters in the input record and moves the pointer to the first column after character-string.
- @character-variable
-
locates the series of characters in the input record that is given by the value of character-variable and moves the pointer to the first column after that series of characters.Example:The following statement reads in the WEEKDAY character variable. The second @1 moves the pointer to the beginning of the input line. The value for SALES is read from the next non-blank column after the value of WEEKDAY:
input @1 day 1. @5 weekday $10. @1 @weekday sales 8.2;
- @(character-expression)
-
locates the series of characters in the input record that is given by the value of character-expression and moves the pointer to the first column after the series.
- +n
-
moves the pointer n columns.Range:a positive integer or zeroTip:If n is not an integer, SAS truncates the decimal value and uses only the integer value. If the value is greater than the length of the input buffer, the pointer moves to column 1 of the next record.Example:This statement moves the pointer to column 23, reads a value for LENGTH from columns 23 through 26, advances the pointer five columns, and reads a value for WIDTH from columns 32 through 35:
input @23 length 4. +5 width 4.;
Example:Moving the Pointer Backward
- +numeric-variable
-
moves the pointer the number of columns that is given by the value of numeric-variable.Range:a positive or negative integer or zeroTip:If numeric-variable is not an integer, SAS truncates the decimal value and uses only the integer value. If numeric-variable is negative, the pointer moves backward. If the current column position becomes less than 1, the pointer moves to column 1. If the value is zero, the pointer does not move. If the value is greater than the length of the input buffer, the pointer moves to column 1 of the next record.Example:Moving the Pointer Backward
- +(expression)
-
moves the pointer the number of columns given by expression.Range:expression must result in a positive or negative integer or zero.Tip:If expression is not an integer, SAS truncates the decimal value and uses only the integer value. If expression is negative, the pointer moves backward. If the current column position becomes less than 1, the pointer moves to column 1. If the value is zero, the pointer does not move. If the value is greater than the length of the input buffer, the pointer moves to column 1 of the next record.
Line Pointer Controls
- #n
-
moves the pointer to record n.Range:a positive integerInteraction:The N= option in the INFILE statement can affect the number of records the INPUT statement reads and the placement of the input pointer after each iteration of the DATA step. See the option N=.Example:The #2 moves the pointer to the second record to read the value for ID from columns 3 and 4:
input name $10. #2 id 3-4;
- #numeric-variable
-
moves the pointer to the record that is given by the value of numeric-variable.Range:a positive integerTip:If the value of numeric-variable is not an integer, SAS truncates the decimal value and uses only the integer value.
Details
When to Use INPUT
Use the INPUT statement
to read raw data from an external file or in-stream data. If your
data are stored in an external file, you can specify the file in an
INFILE statement. The INFILE statement must execute before the INPUT
statement that reads the data records. If your data are in-stream,
a DATALINES statement must precede the data lines in the job stream.
If your data contain semicolons, use a DATALINES4 statement before
the data lines. A DATA step that reads raw data can include multiple
INPUT statements.
You can also use the
INFILE statement to read in-stream data by specifying a filename of
DATALINES in the INFILE statement before the INPUT statement. Using
DATALINES in the INFILE statement enables you to use most of the options
available in the INFILE statement with in-stream data.
To read data that are
already stored in a SAS data set, use a SET statement. To read database
or PC file-format data that are created by other software, use the
SET statement after you access the data with the LIBNAME statement.
See the SAS/ACCESS documentation for more information.
z/OS Specifics: LOG
files that are generated under z/OS and captured with PROC PRINTTO
contain an ASA control character in column 1. If you are using the
INPUT statement to read a LOG file that was generated under z/OS ,
you must account for this character if you use column input or column
pointer controls.
Input Styles
Column Input
With column input,
the column numbers follow the variable name in the INPUT statement.
These numbers indicate where the variable values are found in the
input data records:
input name $ 1-8 age 11-12;
This INPUT statement
can read the following data records:
----+----1----+----2----+ Peterson 21 Morgan 17
Because NAME is a character
variable, a $ appears between the variable name and column numbers.
For more information, see INPUT Statement, Column.
List Input
With list input,
the variable names are simply listed in the INPUT statement. A $ follows
the name of each character variable:
input name $ age;
This INPUT statement
can read data values that are separated by blanks or aligned in columns
(with at least one blank between):
----+----1----+----2----+ Peterson 21 Morgan 17
For more information,
see INPUT Statement, List.
Formatted Input
With formatted input,
an informat follows the variable name in the INPUT statement. The
informat gives the data type and the field width of an input value.
Informats also enable you to read data that are stored in nonstandard
form, such as packed decimal, or numbers that contain special characters
such as commas.
input name $char8. +2 income comma6.;
This INPUT statement
reads these data records correctly:
----+----1----+----2----+ Peterson 21,000 Morgan 17,132
The pointer control
of +2 moves the input pointer to the field that contains the value
for the variable INCOME. For more information, see INPUT Statement, Formatted.
Named Input
With named input,
you specify the name of the variable followed by an equal sign. SAS
looks for a variable name and an equal sign in the input record:
input name= $ age=;
This INPUT statement
reads the following data records correctly:
----+----1----+----2----+ name=Peterson age=21 name=Morgan age=17
For more information,
see INPUT Statement, Named.
Multiple Styles in a Single INPUT Statement
An INPUT statement can
contain any or all of the different input styles:
input idno name $18. team $ 25-30 startwght endwght;
This INPUT statement
reads the following data records correctly:
----+----1----+----2----+----3----+---- 023 David Shaw red 189 165 049 Amelia Serrano yellow 189 165
Pointer Controls
Overview of Pointers
As SAS reads values from the input
data records into the input buffer, it keeps track of its position
with a pointer. The INPUT statement provides three ways to control
the movement of the pointer:
With column and line
pointer controls, you can specify an absolute line number or column
number to move the pointer or you can specify a column or line location
relative to the current pointer position. The following table lists
the pointer controls that are available with the INPUT statement.
Using Column and Line Pointer Controls
Use line pointer controls
within the INPUT statement to move to the next input record or to
define the number of input records per observation. Line pointer controls
specify which input record to read. To read multiple data records
into the input buffer, use the N= option in the INFILE statement to
specify the number of records. If you omit N=, you need to take special
precautions. For more information, see Reading More than One Record per Observation.
Using Line-Hold Specifiers
Use a single trailing
@ to allow the next INPUT statement to read from the same record.
Use a double trailing @ to hold a record for the next INPUT statement
across iterations of the DATA step.
Normally, each INPUT
statement in a DATA step reads a new data record into the input buffer.
When you use a trailing @, the following occurs:
Pointer Location After Reading
Understanding the location
of the input pointer after a value is read is important, especially
if you combine input styles in a single INPUT statement. With column
and formatted input, the pointer reads the columns that are indicated
in the INPUT statement and stops in the next column. With list input,
however, the pointer scans data records to locate data values and
reads a blank to indicate that a value has ended. After reading a
value with list input, the pointer stops in the second column after
the value.
For example, you can
read these data records with list, column, and formatted input:
----+----1----+----2----+----3 REGION1 49670 REGION2 97540 REGION3 86342
After reading a value
for REGION, the pointer stops in column 9.
----+----1----+----2----+----3
REGION1 49670
↑Reading More than One Record per Observation
Using the # Pointer Control
The highest number
that follows the # pointer control in the INPUT statement determines
how many input data records are read into the input buffer. Use the
N= option in the INFILE statement to change the number of records.
For example, in this statement, the highest value after the # is 3:
input @31 age 3. #3 id 3-4 #2 @6 name $20.;
Unless you use N= in
the associated INFILE statement, the INPUT statement reads three input
records each time the DATA step executes.
When each observation
has multiple input records but values from the last record are not
read, you must use a # pointer control in the INPUT statement or N=
in the INFILE statement to specify the last input record. For example,
if there are four records per observation, but only values from the
first two input records are read, use this INPUT statement:
input name $ 1-10 #2 age 13-14 #4;
When you have advanced
to the next record with the / pointer control, use the # pointer control
in the INPUT statement or the N= option in the INFILE statement to
set the number of records that are read into the input buffer. To
move the pointer back to an earlier record, use a # pointer control.
For example, this statement requires the #2 pointer control, unless
the INFILE statement uses the N= option, to read two records:
input a / b #1 @52 c #2;
The INPUT statement
assigns A a value from the first record. The pointer advances to the
next input record to assign B a value. Then the pointer returns from
the second record to column 1 of the first record and moves to column
52 to assign C a value. The #2 pointer control identifies two input
records for each observation so that the pointer can return to the
first record for the value of C.
If the number of input
records per observation varies, use the N= option in the INFILE statement
to give the maximum number of records per observation. For more information,
see the N= option.
Reading Past the End of a Line
When you use @ or +
pointer controls with a value that moves the pointer to or past the
end of the current record and the next value is to be read from the
current column, SAS goes to column 1 of the next record to read it.
It also writes this message to the SAS log:
NOTE: SAS went to a new line when INPUT statement
reached past the end of a line.Use the STOPOVER option
in the INFILE statement to treat this condition as an error and to
stop building the data set.
Positioning the Pointer before the Record
When a column pointer
control tries to move the pointer to a position before the beginning
of the record, the pointer is positioned in column 1. For example,
this INPUT statement specifies that the pointer is located in column
−2 after the first value is read:
data test; input a @(a-3) b; datalines; 2 ;
How Invalid Data Is Handled
When SAS encounters
an invalid character in an input value for the variable indicated,
it
-
sets the value of the variable that is being read to missing or the value that is specified with the INVALIDDATA= system option. For more information see the INVALIDDATA= System Option in SAS System Options: Reference.
The format modifiers
for error reporting control the amount of information that is printed
in the SAS log. Both the ? and ?? modifier suppress the invalid data
message. However, the ?? modifier also resets the automatic variable
_ERROR_ to 0. For example, these two sets of statements are equivalent:
End-of-File
End-of-file occurs when
an INPUT statement reaches the end of the data. If a DATA step tries
to read another record after it reaches an end-of-file, then execution
stops. If you want the DATA step to continue to execute, use the END=
or EOF= option in the INFILE statement. Then you can write SAS program
statements to detect the end-of-file, and to stop the execution of
the INPUT statement but continue with the DATA step. For more information,
see the INFILE Statement.
Arrays
The INPUT statement
can use array references to read input data values. You can use an
array reference in a pointer control if it is enclosed in parentheses.
See Positioning the Pointer with a Character Variable.
Use the array subscript
asterisk (*) to input all elements of a previously defined explicit
array. SAS allows single or multidimensional arrays. Enclose the
subscript in braces, brackets, or parentheses. The form of this statement
is
INPUT array-name{*};You can use arrays with
list, column, or formatted input. However, you cannot input values
to an array that is defined with _TEMPORARY_ and that uses the asterisk
subscript. For example, these statements create variables X1 through
X100 and assign data values to the variables using the 2. informat:
array x{100};
input x{*} 2.;Examples
Example 1: Using Multiple Styles of Input in One INPUT Statement
Example 3: Holding a Record in the Input Buffer
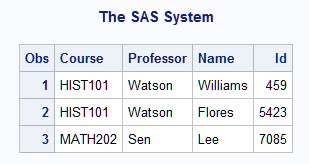
This example reads a
file that contains two types of input data records and creates a SAS
data set from these records. One type of data record contains information
about a particular college course. The second type of record contains
information about the students enrolled in the course. You need two
INPUT statements to read the two records and to assign the values
to different variables that use different formats. Records that contain
class information have a C in column 1; records that contain student
information have an S in column 1, as shown here:
----+----1----+----2----+ C HIST101 Watson S Williams 0459 S Flores 5423 C MATH202 Sen S Lee 7085
To know which INPUT
statement to use, check each record as it is read. Use an INPUT statement
that reads only the variable that tells whether the record contains
class or student.
data schedule(drop=type);
retain Course Professor;
input type $1. @;
if type='C' then
input course $ professor $;
else if type='S' then
do;
input Name $10. Id;
output schedule;
end;
datalines;
C HIST101 Watson
S Williams 0459
S Flores 5423
C MATH202 Sen
S Lee 7085
;
run;
proc print;
run;The first INPUT statement
reads the TYPE value from column 1 of every line. Because this INPUT
statement ends with a trailing @, the next INPUT statement in the
DATA step reads the same line. The IF-THEN statements that follow
check whether the record is a class or student line before another
INPUT statement reads the rest of the line. The INPUT statements without
a trailing @ release the held line. The RETAIN statement saves the
values about the particular college course. The DATA step writes an
observation to the SCHEDULE data set after a student record is read.
Example 4: Holding a Record across Iterations of the DATA Step
This example shows how
to create multiple observations for each input data record. Each record
contains several NAME and AGE values. The DATA step reads a NAME value and an AGE
value, outputs an observation, and then reads another set of NAME
and AGE values to output, and so on, until all the input values in
the record are processed.
data test; input name $ age @@; datalines; John 13 Monica 12 Sue 15 Stephen 10 Marc 22 Lily 17 ;
Example 5: Positioning the Pointer with a Numeric Variable
This example uses a
numeric variable to position the pointer. A raw data file contains
records with the employment figures for several offices of a multinational
company. The input data records are
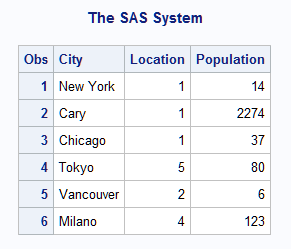
----+----1----+----2----+----3----+ 8 New York 1 USA 14 5 Cary 1 USA 2274 3 Chicago 1 USA 37 22 Tokyo 5 ASIA 80 5 Vancouver 2 CANADA 6 9 Milano 4 EUROPE 123
The first column has
the column position for the office location. The next numeric column
is the region category. The geographic region occurs before the number
of employees in that office.
You determine the office
location by combining the @numeric-variable pointer
control with a trailing @. To read the records, use two INPUT statements.
The first INPUT statement obtains the value for the @ numeric-variable pointer
control. The second INPUT statement uses this value to determine
the column that the pointer moves to.
data office (drop=x);
infile file-specification;
input x @;
if 1<=x<=10 then
input @x City $9.;
else do;
put 'Invalid input at line ' _n_;
delete;
end;
run;The DATA step writes
only five observations to the OFFICE data set. The fourth input data
record is invalid because the value of X is greater than 10. Therefore,
the second INPUT statement does not execute. Instead, the PUT statement
writes a message to the SAS log and the DELETE statement stops processing
the observation.
Example 6: Positioning the Pointer with a Character Variable
This example uses character
variables to position the pointer. The OFFICE data set, created in
Positioning the Pointer with a Numeric Variable, contains a
character variable CITY whose values are the office locations. Suppose
you discover that you need to read additional values from the raw
data file. By using another DATA step, you can combine the @character-variable pointer
control with a trailing @ and the @character-expression pointer
control to locate the values.
If the observations
in OFFICE are still in the order of the original input data records,
you can use this DATA step:
data office2;
set office;
infile file-specification;
array region {5} $ _temporary_
('USA' 'CANADA' 'SA' 'EUROPE' 'ASIA');
input @city Location : 2. @;
input @(trim(region{location})) Population : 4.;
run;The ARRAY statement
assigns initial values to the temporary array elements. These elements
correspond to the geographic regions of the office locations. The
first INPUT statement uses an @character-variable pointer
control. Each record is scanned for the series of characters in the
value of CITY for that observation. Then the value of LOCATION is
read from the next non-blank column. LOCATION is a numeric category
for the geographic region of an office. The second INPUT statement
uses an array reference in the @character-expression pointer
control to determine the location POPULATION in the input records.
The expression also uses the TRIM function to trim trailing blanks
from the character value. This way an exact match is found between
the character string in the input data and the value of the array
element.