How SAS Processes Statements without Macro Activity
The process that
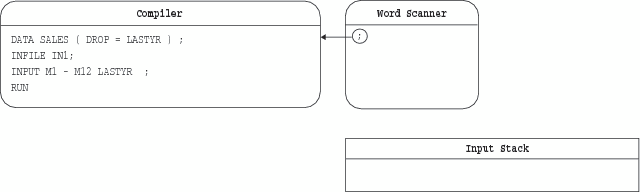
SAS uses to extract words and symbols from the input stack is called tokenization. Tokenization is performed by a component
of SAS called the word scanner, as shown
in The Sample Program before Tokenization. The word scanner starts at the first character in the input
stack and examines each character in turn. In doing so, the word
scanner assembles the characters into tokens. There are four general
types of tokens:
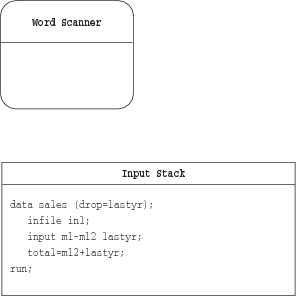
The first SAS statement
in the input stack in the preceding figure contains eight tokens (four
names and four special characters).
When the word scanner
finds a blank or the beginning of a new token, it removes a token
from the input stack and transfers it to the bottom of the queue.
In this
example, when the word scanner pulls the first token from the input
stack, it recognizes the token as the beginning of a DATA step. The
word scanner triggers the DATA step compiler, which begins to request
more tokens. The compiler pulls tokens from the top of the queue,
as shown in the following figure.
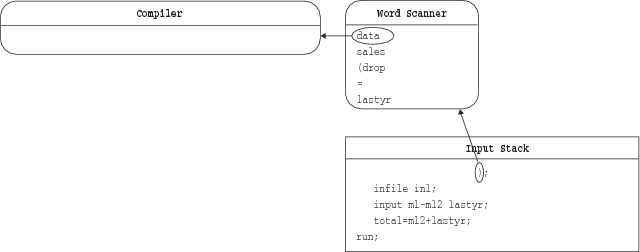
The compiler continues
to pull tokens until it recognizes the end of the DATA step (in this
case, the RUN statement), which is called a DATA step boundary, as
shown in the following figure. When the DATA step compiler recognizes
the end of a step, the step is executed, and the DATA step is complete.