CCHART Statement: SHEWHART Procedure

Constructing Charts for Numbers of Nonconformities (c Charts)
The following notation is used in this section:
|
u |
expected number of nonconformities per unit produced by the process |
|
|
|
number of nonconformities per unit in the ith subgroup |
|
|
|
total number of nonconformities in the ith subgroup |
|
|
|
number of inspection units in the ith subgroup. Typically, |
|
|
|
average number of nonconformities per unit taken across subgroups. The quantity
|
|
|
N |
number of subgroups |
|
|
|
has a central |
Plotted Points
Each point on a c chart represents the total number of nonconformities (![]() ) in a subgroup. For example, Figure 17.24 displays three sections of pipeline that are inspected for defective welds (indicated by an X). Each section represents a subgroup composed of a number of inspection units, which are 1000-foot-long sections. The number of units in the ith subgroup is denoted by
) in a subgroup. For example, Figure 17.24 displays three sections of pipeline that are inspected for defective welds (indicated by an X). Each section represents a subgroup composed of a number of inspection units, which are 1000-foot-long sections. The number of units in the ith subgroup is denoted by ![]() , which is the subgroup sample size. The value of
, which is the subgroup sample size. The value of ![]() can be fractional; Figure 17.24 shows
can be fractional; Figure 17.24 shows ![]() units in the third subgroup.
units in the third subgroup.
Figure 17.24: Terminology for c Charts and u Charts
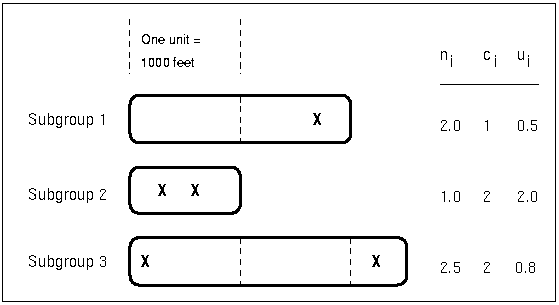
The number of nonconformities in the ith subgroup is denoted by ![]() . The number of nonconformities per unit in the ith subgroup is denoted by
. The number of nonconformities per unit in the ith subgroup is denoted by ![]() . In Figure 17.24, the number of welds per inspection unit in the third subgroup is
. In Figure 17.24, the number of welds per inspection unit in the third subgroup is ![]() .
.
A u chart created with the UCHART statement plots the quantity ![]() for the ith subgroup (see UCHART Statement: SHEWHART Procedure). An advantage of a u chart is that the value of the central line at the ith subgroup does not depend on
for the ith subgroup (see UCHART Statement: SHEWHART Procedure). An advantage of a u chart is that the value of the central line at the ith subgroup does not depend on ![]() . This is not the case for a c chart, and consequently, a u chart is often preferred when the number of units
. This is not the case for a c chart, and consequently, a u chart is often preferred when the number of units ![]() is not constant across subgroups.
is not constant across subgroups.
Central Line
On a c chart, the central line indicates an estimate for ![]() , which is computed as
, which is computed as ![]() . If you specify a known value (
. If you specify a known value (![]() ) for u, the central line indicates the value of
) for u, the central line indicates the value of ![]() .
.
Note that the central line varies with subgroup sample size ![]() . When
. When ![]() for all subgroups, the central line has the constant value
for all subgroups, the central line has the constant value ![]() .
.
Control Limits
You can compute the limits in the following ways:
-
as a specified multiple (k) of the standard error of
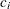 above and below the central line. The default limits are computed with k = 3 (these are referred to as
above and below the central line. The default limits are computed with k = 3 (these are referred to as 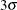 limits).
limits).
-
as probability limits defined in terms of
 , a specified probability that exceeds the limits
, a specified probability that exceeds the limits
The lower and upper control limits, LCLC and UCLC respectively, are given by
|
|
|
|
|
|
|
|
The upper and lower control limits vary with the number of inspection units per subgroup ![]() . If
. If ![]() for all subgroups, the control limits have constant values.
for all subgroups, the control limits have constant values.
|
|
|
|
|
|
|
|
An upper probability limit UCLC for ![]() can be determined using the fact that
can be determined using the fact that
|
|
The upper probability limit UCLC is then calculated by setting
|
|
and solving for UCLC.
A similar approach is used to calculate the lower probability limit LCLC, using the fact that
|
|
The lower probability limit LCLC is then calculated by setting
|
|
and solving for LCLC. This assumes that the process is in statistical control and that ![]() has a Poisson distribution. For more information, refer to Johnson, Kotz, and Kemp (1992). Note that the probability limits vary with the number of inspection units per subgroup (
has a Poisson distribution. For more information, refer to Johnson, Kotz, and Kemp (1992). Note that the probability limits vary with the number of inspection units per subgroup (![]() ) and are asymmetric about the central line.
) and are asymmetric about the central line.
If a standard value ![]() is available for u, replace
is available for u, replace ![]() with
with ![]() in the formulas for the control limits. You can specify parameters for the limits as follows:
in the formulas for the control limits. You can specify parameters for the limits as follows:
-
Specify k with the SIGMAS= option or with the variable
_SIGMAS_in a LIMITS= data set. -
Specify
with the ALPHA= option or with the variable _ALPHA_in a LIMITS= data set. -
Specify a constant nominal sample size
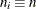 for the control limits with the LIMITN= option or with the variable
for the control limits with the LIMITN= option or with the variable _LIMITN_in a LIMITS= data set. -
Specify
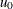 with the U0= option or with the variable
with the U0= option or with the variable _U_in a LIMITS= data set.