The MVPMONITOR Procedure

The MVPMONITOR procedure accepts a single primary input data set of one of three types.
-
A DATA= data set contains new process data to be analyzed by using an existing PCA model (Phase II analysis).
-
A HISTORY= data set contains process data and the accompanying scores, residuals, and statistics produced by applying a PCA model. The process data can be the original data that was used to create the model (Phase I analysis) or subsequent data that was analyzed by using a previously created model (Phase II analysis).
-
A TABLE= data set contains a summary of score charts, SPE charts, or
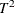 charts, which consists of the statistics, control limits, and other information.
charts, which consists of the statistics, control limits, and other information.
These options are mutually exclusive. If you do not specify an option identifying a primary input data set, PROC MVPMONITOR uses the most recently created SAS data set as a DATA= data set.
When you specify a DATA= data set, you must also specify a LOADINGS= data set that contains loadings and other information describing the PCA model. When you specify a HISTORY= data set, you must also specify a LOADINGS= data set if you specify the CONTRIBUTIONS option in a TSQUARECHART statement.
A DATA= data set provides the process measurement data for a Phase II analysis. In addition to the process variables, a DATA= data set can include the following:
When you specify a DATA= data set, you must also specify a LOADINGS= data set that contains the loadings for the principal component model that describes the variation of the process. These loadings are used to score the new data from the DATA= data set. The process variables in the LOADINGS= data set must have the same names as those in the DATA= data set.
A HISTORY= data set provides the input data set for a Phase I or Phase II analysis. In addition to the original process variables, it
contains principal component scores, residuals, SPE and ![]() statistics, and a count of the observations that are used to construct the principal component model, as summarized in Table 13.5.
statistics, and a count of the observations that are used to construct the principal component model, as summarized in Table 13.5.
Table 13.5: Variables in the HISTORY= Data Set
|
Variable |
Description |
|---|---|
|
Prin1–Prinj |
Principal component scores |
|
R_ |
Residuals |
|
_NOBS_ |
Number of observations used to build the principal component model |
|
_SPE_ |
Squared prediction error (SPE) |
|
_TSQUARE_ |
|
A HISTORY= data set must include variables that contain principal component scores. The score variables names must consist
of a common prefix followed by the numbers 1, 2, …, j, where j is the number of principal components. By default, the common prefix is Prin. You can use the PREFIX= option to specify another prefix for score variables.
If the number of principal components is less than the total number of process variables, the HISTORY= data set should also
contain residual variables. A residual variable name consists of a common prefix followed by the corresponding process variable
name. The default residual variable prefix is R_. For example, if the process variables are A, B, and C, the default residual variable names are R_A, R_B, and R_C. You can use the RPREFIX= option to specify a different residual variable prefix.
Note: Usually you create a HISTORY= data set by specifying the PROC MVPMODEL OUT= option or the PROC MVPMONITOR OUTHISTORY= option. If the PREFIX= or RPREFIX= option is used when such an output data set is created, you must specify the same prefixes to identify the score and residual variables when you read it as a HISTORY= data set.
The LOADINGS= data set contains the following information about the principal component model:
-
eigenvalues of the correlation or covariance matrix used to construct the model
-
principal component loadings
-
process variable means used to center the variable values
-
process variable standard deviations used to scale the variable values
You can produce a LOADINGS= data set by using the PROC MVPMODEL OUTLOADINGS= option. Table 13.6 lists the variables that are required in a LOADINGS= data set.
Table 13.6: Variables in the LOADINGS= Data Set
|
Variable |
Description |
|---|---|
|
_VALUE_ |
The value contained in process variables for a given observation |
|
_NOBS_ |
Number of observations used to build the principal component model |
|
_PC_ |
Principal component number; 0 for the observation that contains eigenvalues |
|
process variables |
Values associated with the process variables |
Valid values for the _VALUE_ variable are as follows:
- EIGEN
-
eigenvalues from the principal component analysis
- LOADING
-
principal component loadings
- MEAN
-
process variable means
- STD
-
process variable standard deviations
The LOADINGS= data set contains one EIGEN observation and j LOADING observations, where j is the number of principal components in the model. The presence of a MEAN observation indicates that the process variables were centered when the principal component model was constructed, and the presence of a STD observation indicates that the process variables were scaled when the principal component model was constructed. The means and standard deviations are used to center and scale new data in a Phase II analysis.
A TABLE= data set contains a summary of one or more score charts, SPE charts, or ![]() control charts. Usually, you create a TABLE= data set by specifying the OUTTABLE= option in a SCORECHART, SPECHART, or TSQUARECHART statement. Each type of TABLE= data set contains different variables, and when you specify a TABLE= data set you can only
specify chart statements of the corresponding type. For example, if you use a TABLE= data set that contains SPE chart summary
data, you cannot specify a SCORECHART or TSQUARECHART statement.
control charts. Usually, you create a TABLE= data set by specifying the OUTTABLE= option in a SCORECHART, SPECHART, or TSQUARECHART statement. Each type of TABLE= data set contains different variables, and when you specify a TABLE= data set you can only
specify chart statements of the corresponding type. For example, if you use a TABLE= data set that contains SPE chart summary
data, you cannot specify a SCORECHART or TSQUARECHART statement.
You can use a TABLE= data set to display previously created control charts or to specify custom control limits by computing
your own _LCL_ and _UCL_ values.
Table 13.7, Table 13.8, and Table 13.9 list the variables that are contained in the three types of TABLE= data set.
Note:
-
SPE chart and
chart TABLE= data sets contain one observation per time value. Score chart TABLE= data sets contain one observation for each
principal component per time value.
-
SPE chart and
chart TABLE= data sets contain residual variables corresponding to the process variables. Each residual variable has the
same name as the corresponding process variable
Table 13.7: Score Chart TABLE= Data Set Variables
|
Variable |
Description |
|---|---|
|
|
Principal component number |
|
|
Flag that indicates control limit was exceeded |
|
|
Lower control limit |
|
|
Center line |
|
|
Principal component score |
|
series |
Optional SERIES variable |
|
|
Multiple of score standard deviation used to compute control limits |
|
time |
Optional TIME variable |
|
|
Upper control limit |
Table 13.8: SPE Chart TABLE= Data Set Variables
|
Variable |
Description |
|---|---|
|
|
Probability ( |
|
|
Flag to indicate control limit was exceeded |
|
|
Lower control limit |
|
|
Center line |
|
residuals |
Residual variables |
|
series |
Optional SERIES variable |
|
|
Squared prediction error (SPE) statistic |
|
time |
Optional TIME variable |
|
|
Upper control limit |
Table 13.9: ![]() Chart TABLE= Data Set Variables
Chart TABLE= Data Set Variables
|
Variable |
Description |
|---|---|
|
|
Probability ( |
|
|
Flag to indicate control limit was exceeded |
|
|
Lower control limit |
|
|
Center line |
|
residuals |
Residual variables |
|
series |
Optional SERIES variable |
|
time |
Optional TIME variable |
|
|
|
|
|
Upper control limit |