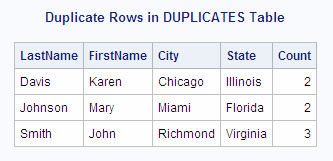
Counting Duplicate Rows in a Table
Background Information
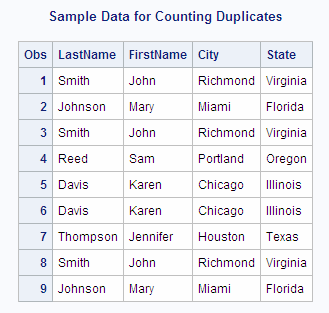
data Duplicates; input LastName $ FirstName $ City $ State $; datalines; Smith John Richmond Virginia Johnson Mary Miami Florida Smith John Richmond Virginia Reed Sam Portland Oregon Davis Karen Chicago Illinois Davis Karen Chicago Illinois Thompson Jennifer Houston Texas Smith John Richmond Virginia Johnson Mary Miami Florida ;
Copyright © SAS Institute Inc. All rights reserved.