The SURVEYLOGISTIC Procedure
- Overview
- Getting Started
-
Syntax
 PROC SURVEYLOGISTIC StatementBY StatementCLASS StatementCLUSTER StatementCONTRAST StatementDOMAIN StatementEFFECT StatementESTIMATE StatementFREQ StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementOUTPUT StatementREPWEIGHTS StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementUNITS StatementWEIGHT Statement
PROC SURVEYLOGISTIC StatementBY StatementCLASS StatementCLUSTER StatementCONTRAST StatementDOMAIN StatementEFFECT StatementESTIMATE StatementFREQ StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementOUTPUT StatementREPWEIGHTS StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementUNITS StatementWEIGHT Statement -
DetailsMissing ValuesModel SpecificationModel FittingSurvey Design InformationLogistic Regression Models and ParametersVariance EstimationDomain AnalysisHypothesis Testing and EstimationLinear Predictor, Predicted Probability, and Confidence LimitsOutput Data SetsDisplayed OutputODS Table NamesODS Graphics
-
Examples
- References
Let
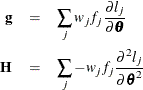
be the gradient vector and the Hessian matrix, where ![]() is the log likelihood for the jth observation. With a starting value of
is the log likelihood for the jth observation. With a starting value of ![]() , the pseudo-estimate
, the pseudo-estimate ![]() of
of ![]() is obtained iteratively until convergence is obtained:
is obtained iteratively until convergence is obtained:
where ![]() and
and ![]() are evaluated at the ith iteration
are evaluated at the ith iteration ![]() . If the log likelihood evaluated at
. If the log likelihood evaluated at ![]() is less than that evaluated at
is less than that evaluated at ![]() , then
, then ![]() is recomputed by step-halving or ridging. The iterative scheme continues until convergence is obtained—that is, until
is recomputed by step-halving or ridging. The iterative scheme continues until convergence is obtained—that is, until ![]() is sufficiently close to
is sufficiently close to ![]() . Then the maximum likelihood estimate of
. Then the maximum likelihood estimate of ![]() is
is ![]() .
.