The ADAPTIVEREG Procedure

The PROC ADAPTIVEREG statement invokes the procedure.
Table 25.1 summarizes the options available in the PROC ADAPTIVEREG statement.
Table 25.1: PROC ADAPTIVEREG Statement Options
|
Option |
Description |
|---|---|
|
Data Set Options |
|
|
Specifies the input SAS data set |
|
|
Names a data set that contains test data |
|
|
Names a data set that contains validation data |
|
|
Computational Options |
|
|
Sets optimization parameters for fitting generalized linear models |
|
|
Sets the fuzzy comparison criterion in selection |
|
|
Sets the singularity tolerance |
|
|
Display Options |
|
|
Sets the length of effect names in tables and output data sets |
|
|
Controls plots produced through ODS Graphics |
|
|
Displays detailed modeling information |
|
|
Other Options |
|
|
Requests the computation in single-threaded mode |
|
|
Requests a data set that contains the design matrix |
|
|
Sets the seed used for pseudo-random number generation |
|
|
Specifies the number of threads for the computation |
|
You can specify the following options.
- DATA=SAS-data-set
-
specifies the SAS data set to be read by PROC ADAPTIVEREG. If you do not specify the DATA= option, PROC ADAPTIVEREG uses the most recently created SAS data set.
- DETAILS<=(detail-options)>
-
requests detailed model fitting information. You can specify the following detail-options:
If you do not specify a detail-option, PROC ADAPTIVEREG produces all the preceding tables by default.
- NAMELEN=number
-
specifies the length to which long effect names are shortened. The default and minimum value is 20.
- NLOPTIONS(options)
-
specifies options for the nonlinear optimization methods if you are applying the multivariate adaptive regression splines algorithm to generalized linear models. You can specify the following options:
-
ABSCONV=r
ABSTOL=r -
specifies an absolute function convergence criterion by which minimization stops when
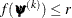 , where
, where 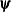 is the vector of parameters in the optimization and
is the vector of parameters in the optimization and 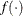 is the objective function. The default value of r is the negative square root of the largest double-precision value, which serves only as a protection against overflows.
is the objective function. The default value of r is the negative square root of the largest double-precision value, which serves only as a protection against overflows.
-
ABSFCONV=r
ABSFTOL=r -
specifies an absolute function difference convergence criterion. For all techniques except NMSIMP, termination requires a small change of the function value in successive iterations,
![\[ |f(\bpsi ^{(k-1)}) - f(\bpsi ^{(k)})| \leq r \]](images/statug_adaptivereg0004.png)
where
denotes the vector of parameters that participate in the optimization and is the objective function. The same formula is used for the NMSIMP technique, but 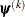 is defined as the vertex with the lowest function value, and
is defined as the vertex with the lowest function value, and 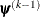 is defined as the vertex with the highest function value in the simplex. The default value is r=0.
is defined as the vertex with the highest function value in the simplex. The default value is r=0.
-
ABSGCONV=r
ABSGTOL=r -
specifies an absolute gradient convergence criterion. Termination requires the maximum absolute gradient element to be small,
![\[ \max _ j |g_ j(\bpsi ^{(k)})| \leq r \]](images/statug_adaptivereg0007.png)
where
denotes the vector of parameters that participate in the optimization and 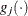 is the gradient of the objective function with respect to the jth parameter. This criterion is not used by the NMSIMP technique. The default value is r = 1E–5.
is the gradient of the objective function with respect to the jth parameter. This criterion is not used by the NMSIMP technique. The default value is r = 1E–5.
-
FCONV=r
FTOL=r -
specifies a relative function convergence criterion. For all techniques except NMSIMP, termination requires a small relative change of the function value in successive iterations,
![\[ \frac{|f(\bpsi ^{(k)}) - f(\bpsi ^{(k-1)})|}{|f(\bpsi ^{(k-1)})|} \leq r \]](images/statug_adaptivereg0009.png)
where
denotes the vector of parameters that participate in the optimization and is the objective function. The same formula is used for the NMSIMP technique, but is defined as the vertex with the lowest function value, and is defined as the vertex with the highest function value in the simplex. The default is r 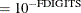 , where FDIGITS is by default
, where FDIGITS is by default 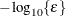 and
and  is the machine precision.
is the machine precision.
-
GCONV=r
GTOL=r -
specifies a relative gradient convergence criterion. For all techniques except CONGRA and NMSIMP, termination requires the normalized predicted function reduction to be small,
![\[ \frac{\mb{g}(\bpsi ^{(k)})^\prime [\bH ^{(k)}]^{-1} \mb{g}(\bpsi ^{(k)})}{|f(\bpsi ^{(k)})| } \leq r \]](images/statug_adaptivereg0013.png)
where
denotes the vector of parameters that participate in the optimization, is the objective function, and 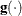 is the gradient. For the CONGRA technique (where a reliable Hessian estimate
is the gradient. For the CONGRA technique (where a reliable Hessian estimate 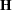 is not available), the following criterion is used:
is not available), the following criterion is used:
![\[ \frac{\parallel \mb{g}(\bpsi ^{(k)}) \parallel _2^2 \quad \parallel \mb{s}(\bpsi ^{(k)}) \parallel _2}{\parallel \mb{g}(\bpsi ^{(k)}) - \mb{g}(\bpsi ^{(k-1)}) \parallel _2 |f(\bpsi ^{(k)})| } \leq r \]](images/statug_adaptivereg0016.png)
This criterion is not used by the NMSIMP technique. The default value is r = 1E–8.
- HESSIAN=hessian-options
-
specifies the Hessian matrix type used in the optimization of likelihood functions, if the Newton-Raphson technique is used. You can specify the following hessian-options:
The default is HESSIAN=EXPECTED.
-
MAXFUNC=n
MAXFU=n -
specifies the maximum number of function calls in the optimization process. The default values are as follows, depending on the optimization technique:
-
TRUREG, NRRIDG, and NEWRAP: 125
-
QUANEW and DBLDOG: 500
-
CONGRA: 1000
-
NMSIMP: 3000
The optimization can terminate only after completing a full iteration. Therefore, the number of function calls that are actually performed can exceed the number that is specified by this option. You can select the optimization technique by specifying the TECHNIQUE= option.
-
-
MAXITER=n
MAXIT=n -
specifies the maximum number of iterations in the optimization process. The default values are as follows, depending on the optimization technique:
-
TRUREG, NRRIDG, and NEWRAP: 50
-
QUANEW and DBLDOG: 200
-
CONGRA: 400
-
NMSIMP: 1000
These default values also apply when n is specified as a missing value. You can select the optimization technique by specifying the TECHNIQUE= option.
-
- MAXTIME=r
-
specifies an upper limit of r seconds of CPU time for the optimization process. The time is checked only at the end of each iteration. Therefore, the actual run time might be longer than the specified time. By default, CPU time is not limited.
-
MINITER=n
MINIT=n -
specifies the minimum number of iterations. The default value is 0. If you request more iterations than are actually needed for convergence to a stationary point, the optimization algorithms can behave strangely. For example, the effect of rounding errors can prevent the algorithm from continuing for the required number of iterations.
- TECHNIQUE=keyword
-
specifies the optimization technique to obtain maximum likelihood estimates for nonnormal distributions. You can choose from the following techniques by specifying the appropriate keyword:
- CONGRA
-
performs a conjugate-gradient optimization.
- DBLDOG
-
performs a version of double-dogleg optimization.
- NEWRAP
-
performs a Newton-Raphson optimization that combines a line-search algorithm with ridging.
- NMSIMP
-
performs a Nelder-Mead simplex optimization.
- NONE
-
performs no optimization.
- NRRIDG
-
performs a Newton-Raphson optimization with ridging.
- QUANEW
-
performs a dual quasi-Newton optimization.
- TRUREG
-
performs a trust-region optimization.
The default is TECHNIQUE=NEWRAP.
For more information about these optimization methods, see the section Choosing an Optimization Algorithm in Chapter 19: Shared Concepts and Topics.
-
ABSCONV=r
- NOTHREADS
-
forces single-threaded execution of the analytic computations. This overrides the SAS system option THREADS | NOTHREADS. Specifying this option is equivalent to specifying the NTHREADS=1 option.
- OUTDESIGN<(options)>=SAS-data-set
-
creates a data set that contains the design matrix of constructed basis functions. The design matrix column names consist of a prefix followed by an index. The default naming prefix is
_X. The default output is the design matrix of basis functions after backward selection.You can specify the following options in parentheses to control the content of the OUTDESIGN= data set:
-
PLOTS <(global-plot-options)> <= plot-request <(options)>>
PLOTS <(global-plot-options)> <= (plot-request <(options)> <... plot-request <(options)>>)> -
controls the plots produced through ODS Graphics. When you specify only one plot-request, you can omit the parentheses around the plot-request. For example:
plots=all plots=components(unpack) plots(unpack)=(components diagnostics)
ODS Graphics must be enabled before plots can be requested. For example:
ods graphics on; proc adaptivereg plots=all; model y=x1 x2; run; ods graphics off;
For more information about enabling and disabling ODS Graphics, see the section Enabling and Disabling ODS Graphics in Chapter 21: Statistical Graphics Using ODS.
You can specify the following global-plot-option, which applies to all plots that the ADAPTIVEREG procedure generates:
You can specify the following plot-requests and their options:
- SEED=number
-
specifies an integer used to start the pseudorandom number generator for random cross validation and random partitioning of data for training, testing, and validation. If you do not specify a seed, or if you specify a value less than or equal to 0, the seed is generated from the time of day, which is read from the computer’s clock.
-
SELFUZZ=number
SELECTFUZZ=number -
sets the fuzzy comparison criterion when PROC ADAPTIVEREG examines candidate basis functions in forward and backward selection stages. The fuzzy comparison criterion is also used in stepwise selection for CLASS variables. A candidate is considered to be the best one only when its improvement is better than the current optimum with the extra amount number. By default, number is
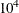 times the machine epsilon. The default number is approximately
times the machine epsilon. The default number is approximately 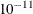 on most machines.
on most machines.
-
SINGULAR=number
EPSILON=number -
sets the tolerance for testing singularity of the
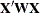 matrix that is formed from the design matrix
matrix that is formed from the design matrix 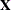 . Roughly, the test requires that a pivot be at least this number times the original diagonal value. By default, number is
. Roughly, the test requires that a pivot be at least this number times the original diagonal value. By default, number is 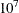 times the machine epsilon. The default number is approximately
times the machine epsilon. The default number is approximately 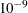 on most machines.
on most machines.
- TESTDATA=SAS-data-set
-
names a SAS data set that contains test data. This data set must contain all the variables specified in the MODEL statement. Furthermore, when a BY statement is used and the TESTDATA=data set contains any of the BY variables, then the TESTDATA= data set must also contain all the BY variables sorted in the order of the BY variables. In this case, only the test data for a specific BY group are used with the corresponding BY group in the analysis data. If the TESTDATA= data set contains none of the BY variables, then the entire TESTDATA = data set is used with each BY group of the analysis data.
If you specify a TESTDATA= data set, then you cannot also specify a PARTITION statement to reserve observations for testing.
- NTHREADS=n
-
specifies the number of threads for analytic computations and overrides the SAS system option THREADS | NOTHREADS. If you do not specify the NTHREADS= option or if you specify NTHREADS=0, the number of threads is determined based on the data size and the number of CPUs on the host on which the analytic computations execute. If the specified number of threads is more than the number of actual CPUs, PROC ADAPTIVEREG by default sets the value to the number of actual CPUs.
- VALDATA=SAS-data-set
-
names a SAS data set that contains validation data. This data set must contain all the variables specified in the MODEL statement. Furthermore, when a BY statement is used and the VALDATA= data set contains any of the BY variables, then the VALDATA= data set must also contain all the BY variables sorted in the order of the BY variables. In this case, only the validation data for a specific BY group are used with the corresponding BY group in the analysis data. If the VALDATA= data set contains none of the BY variables, then the entire VALDATA = data set is used with each BY group of the analysis data.
If you specify a VALDATA= data set, then you cannot also specify a PARTITION statement to reserve observations for validation.