The IRT Procedure

This example shows you the features that PROC IRT provides for unidimensional analysis. The data set comes from the 1978 Quality of American Life Survey. The survey was administered to a sample of all U.S. residents aged 18 years and older in 1978. In this survey, subjects were asked to rate their satisfaction with many different aspects of their lives. This example selects eight items. These items are designed to measure people’s satisfaction in the following areas on a seven-point scale: community, neighborhood, dwelling unit, life in the United States, amount of education received, own health, job, and how spare time is spent. For illustration purposes, the first five items are dichotomized and the last three items are collapsed into three levels.
The following DATA step creates the data set IrtUni.
data IrtUni; input item1-item8 @@; datalines; 1 0 0 0 1 1 2 1 1 1 1 1 1 3 3 3 0 1 0 0 1 1 1 1 1 0 0 1 0 1 2 3 0 0 0 0 0 1 1 1 1 0 0 1 0 1 3 3 0 0 0 0 0 1 1 3 0 0 1 0 0 1 2 2 0 1 0 0 1 1 ... more lines ... 3 3 0 1 0 0 1 2 2 1 ;
Because all the items are designed to measure subjects’ satisfaction in different aspects of their lives, it is reasonable to start with a unidimensional IRT model. The following statements fit such a model by using several user-specified options:
ods graphics on; proc irt data=IrtUni link=probit pinitial itemfit plots=ICC; var item1-item8; model item1-item4/resfunc=twop, item5-item8/resfunc=graded; run; ods graphics off;
The ODS GRAPHICS ON statement invokes the ODS Graphics environment and displays the plots, such as the item characteristic curve plot. For more information about ODS Graphics, see Chapter 21: Statistical Graphics Using ODS.
The first option is the LINK= option, which specifies that the link function be the probit link. Next, you request initial parameter estimates by using the PINITIAL option. Item fit statistics are displayed using the ITEMFIT option. In the PROC IRT statement, you can use the PLOTS option to request different plots. In this example, you request item characteristic curves by using the PLOTS=ICC option.
In this example, you use the MODEL
statement to specify different response models for different items. The specifications in the MODEL
statement suggest that the first four items, item1 to item4, are fitted using the two-parameter model, whereas the last four items, item5 to item8, are fitted using the graded response model.
Output 53.1.1 displays two tables. From the "Modeling Information" table, you can observe that the link function has changed from the default
LOGIT link to the specified PROBIT link. The "Item Information" table shows that item1 to item5 each have two levels and item6 to item8 each have three levels. The last column shows the raw values of these different levels.
PROC IRT produces the "Eigenvalues of the Polychoric Correlation Matrix" table in Output 53.1.2 by default. You can use these eigenvalues to assess the dimension of latent factors. For this example, the fact that only the first eigenvalue is greater than 1 suggests that a one-factor model for the items is reasonable.
Output 53.1.2: Eigenvalues of Polychoric Correlations
| Eigenvalues of the Polychoric Correlation Matrix | ||||
|---|---|---|---|---|
| Eigenvalue | Difference | Proportion | Cumulative | |
| 1 | 3.11870486 | 2.12497677 | 0.3898 | 0.3898 |
| 2 | 0.99372809 | 0.10025986 | 0.1242 | 0.5141 |
| 3 | 0.89346823 | 0.03116998 | 0.1117 | 0.6257 |
| 4 | 0.86229826 | 0.10670185 | 0.1078 | 0.7335 |
| 5 | 0.75559640 | 0.17795713 | 0.0944 | 0.8280 |
| 6 | 0.57763928 | 0.10080017 | 0.0722 | 0.9002 |
| 7 | 0.47683911 | 0.15511333 | 0.0596 | 0.9598 |
| 8 | 0.32172578 | 0.0402 | 1.0000 | |
The PINITIAL option in the PROC IRT statement displays the "Initial Item Parameter Estimates" table, shown in Output 53.1.3.
Output 53.1.3: Initial Parameter Estimates
| Initial Item Parameter Estimates | |||
|---|---|---|---|
| Response Model |
Item | Parameter | Estimate |
| TwoP | item1 | Difficulty | 0.26428 |
| Slope | 1.05346 | ||
| item2 | Difficulty | 0.58640 | |
| Slope | 0.93973 | ||
| item3 | Difficulty | 0.44607 | |
| Slope | 0.82826 | ||
| item4 | Difficulty | 0.50157 | |
| Slope | 0.50906 | ||
| Graded | item5 | Threshold 1 | -0.86792 |
| Slope | 0.41380 | ||
| item6 | Threshold 1 | -0.59512 | |
| Threshold 2 | 2.00678 | ||
| Slope | 0.36063 | ||
| item7 | Threshold 1 | -0.90743 | |
| Threshold 2 | 0.69335 | ||
| Slope | 0.64191 | ||
| item8 | Threshold 1 | -1.18209 | |
| Threshold 2 | 0.26959 | ||
| Slope | 0.67591 | ||
Output 53.1.4 includes tables that are related to the optimization. The "Optimization Information" table shows that the log likelihood
is approximated by using seven adaptive Gauss-Hermite quadrature points and then maximized by using the quasi-Newton algorithm.
The number of free parameters in this example is 19. The "Iteration History" table shows the number of function evaluations,
the objective function (–![]() likelihood divided by number of subjects) values, the objective function change, and the maximum gradient for each iteration.
This information is very useful in monitoring the optimization status. Output 53.1.4 shows the convergence status at the bottom. The optimization converges according to the GCONV=0.00000001 criterion.
likelihood divided by number of subjects) values, the objective function change, and the maximum gradient for each iteration.
This information is very useful in monitoring the optimization status. Output 53.1.4 shows the convergence status at the bottom. The optimization converges according to the GCONV=0.00000001 criterion.
Output 53.1.4: Optimization Information
| Iteration History | ||||
|---|---|---|---|---|
| Iteration | Evaluations | Objective Function |
Change | Max Gradient |
| 0 | 2 | 6.19423730 | 6.19423730 | 0.015501 |
| 1 | 5 | 6.19269781 | -0.00153950 | 0.005787 |
| 2 | 8 | 6.19256587 | -0.00013194 | 0.003813 |
| 3 | 10 | 6.19249856 | -0.00006732 | 0.003278 |
| 4 | 12 | 6.19245371 | -0.00004485 | 0.004635 |
| 5 | 15 | 6.19243639 | -0.00001732 | 0.001284 |
| 6 | 18 | 6.19242942 | -0.00000696 | 0.00049 |
| 7 | 21 | 6.19242884 | -0.00000058 | 0.000191 |
| 8 | 24 | 6.19242871 | -0.00000013 | 0.000104 |
| 9 | 27 | 6.19242867 | -0.00000004 | 0.000051 |
| 10 | 30 | 6.19242867 | -0.00000001 | 0.000011 |
Output 53.1.5 displays the model fit and item fit statistics. Note that the item fit statistics apply only to the binary items. That is
why these fit statistics are missing for item6 to item8.
Output 53.1.5: Fit Statistics
| Item Fit Statistics | ||||||
|---|---|---|---|---|---|---|
| Response Model |
Item | DF | Pearson Chi-Square |
Pr > P ChiSq | LR Chi-Square |
Pr > LR ChiSq |
| TwoP | item1 | 8 | 34.16545 | <.0001 | 49.39743 | <.0001 |
| item2 | 8 | 30.34646 | 0.0002 | 37.52865 | <.0001 | |
| item3 | 8 | 27.54546 | 0.0006 | 36.34505 | <.0001 | |
| item4 | 8 | 22.75981 | 0.0037 | 26.13409 | 0.0010 | |
| Graded | item5 | 8 | 18.32369 | 0.0189 | 19.68488 | 0.0116 |
| item6 | . | . | . | . | . | |
| item7 | . | . | . | . | . | |
| item8 | . | . | . | . | . | |
The last table for this example is the "Item Parameter Estimates " table in Output 53.1.6. This table contains parameter estimates, standard errors, and p-values. These p-values suggest that all the parameters are significantly different from zero.
Output 53.1.6: Parameter Estimates
| Item Parameter Estimates | |||||
|---|---|---|---|---|---|
| Response Model |
Item | Parameter | Estimate | Standard Error |
Pr > |t| |
| TwoP | item1 | Difficulty | 0.27342 | 0.08301 | 0.0005 |
| Slope | 0.98381 | 0.14145 | <.0001 | ||
| item2 | Difficulty | 0.60268 | 0.10047 | <.0001 | |
| Slope | 0.90009 | 0.13112 | <.0001 | ||
| item3 | Difficulty | 0.46110 | 0.10061 | <.0001 | |
| Slope | 0.79521 | 0.11392 | <.0001 | ||
| item4 | Difficulty | 0.50686 | 0.14410 | 0.0002 | |
| Slope | 0.50431 | 0.08567 | <.0001 | ||
| Graded | item5 | Threshold | -0.79750 | 0.18708 | <.0001 |
| Slope | 0.45385 | 0.08238 | <.0001 | ||
| item6 | Threshold 1 | -0.59139 | 0.19858 | 0.0014 | |
| Threshold 2 | 2.02708 | 0.39593 | <.0001 | ||
| Slope | 0.35770 | 0.06777 | <.0001 | ||
| item7 | Threshold 1 | -0.82130 | 0.12753 | <.0001 | |
| Threshold 2 | 0.64441 | 0.11431 | <.0001 | ||
| Slope | 0.72674 | 0.09312 | <.0001 | ||
| item8 | Threshold 1 | -1.08124 | 0.14132 | <.0001 | |
| Threshold 2 | 0.25166 | 0.09535 | 0.0042 | ||
| Slope | 0.76383 | 0.09753 | <.0001 | ||
Item characteristic curves (ICC) are also produced in this example. By default, these ICC plots are displayed in panels. To display an individual ICC plot for each item, use the UNPACK suboption in the PLOTS= option in the PROC IRT statement.
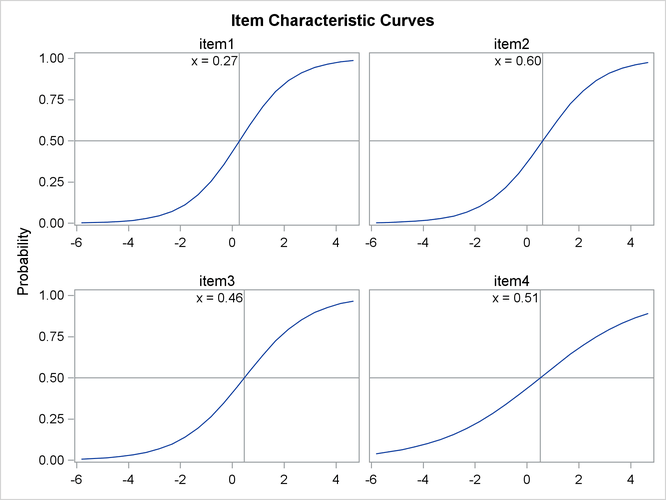
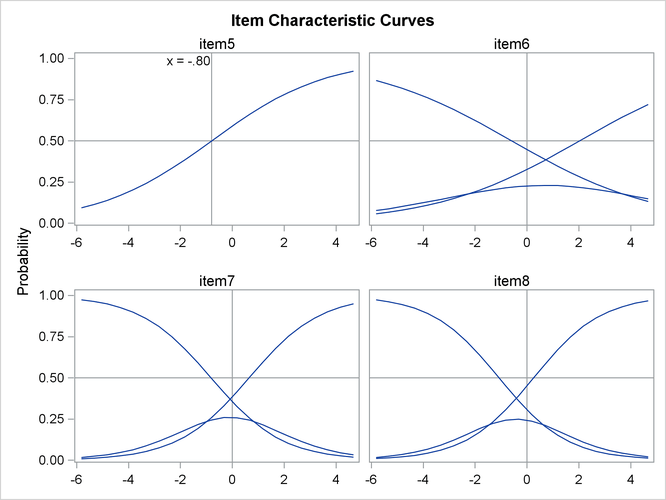
Now, suppose your research hypothesis includes some equality constraints on the model parameters—for example, the slopes for the first four items are equal. Such equality constraints can be specified easily by using the EQUALITY statement. In the following example, the slope parameters of the first four items are equal:
proc irt data=IrtUni; var item1-item8; model item1-item4/resfunc=twop, item5-item8/resfunc=graded; equality item1-item4/parm=[slope]; run;
To estimate the factor score for each subject and add these scores to the original data set, you can use the OUT=
option in the PROC IRT
statement. PROC IRT provides three factor score estimation methods: maximum likelihood (ML), maximum a posteriori (MAP),
and expected a posteriori (EAP). You can choose an estimation method by using the SCOREMETHOD=
option in the PROC IRT
statement. The default method is maximum a posteriori. In the following, factor scores along with the original data are saved
to a SAS data set called IrtUniFscore:
proc irt data=IrtUni out=IrtUniFscore;
var item1-item8;
model item1-item4/resfunc=twop,
item5-item8/resfunc=graded;
equality item1-item4/parm=[slope];
run;
Sometimes you might find it useful to sort the items based on the estimated difficulty or slope parameters. You can do this by outputting the ODS tables for the estimates into data sets and then sorting the items by using PROC SORT. A simulated data set is used to show the steps.
The following DATA step creates the data set IrtSimu:
data IrtSimu; input item1-item25 @@; datalines; 1 1 1 0 1 1 0 0 1 1 0 0 0 0 1 0 1 1 1 0 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0 0 0 0 1 1 0 0 0 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 0 0 0 1 1 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 0 1 0 0 0 1 0 1 1 0 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 0 0 0 0 0 0 0 1 0 1 0 1 0 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 ... more lines ... 1 1 0 1 1 1 1 1 1 1 0 1 1 0 0 0 1 1 0 1 1 1 1 1 1 0 0 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 1 1 0 1 1 1 1 1 1 ;
First, you build the model and output the parameter estimates table into a SAS data set by using the ODS OUTPUT statement:
proc irt data=IrtSimu link=probit; var item1-item25; ods output ParameterEstimates=ParmEst; run;
Output 53.1.8 shows the "Item Parameter Estimates" table. Notice that the difficulty and slope parameters are in the same column. The reason for this is to avoid having an extremely wide table when each item has a lot of parameters.
Output 53.1.8: Basic Information
| Item Parameter Estimates | ||||
|---|---|---|---|---|
| Item | Parameter | Estimate | Standard Error |
Pr > |t| |
| item1 | Difficulty | -1.32543 | 0.09769 | <.0001 |
| Slope | 1.44263 | 0.16091 | <.0001 | |
| item2 | Difficulty | -0.99702 | 0.07431 | <.0001 |
| Slope | 1.82221 | 0.19006 | <.0001 | |
| item3 | Difficulty | -1.24965 | 0.08962 | <.0001 |
| Slope | 1.58762 | 0.17495 | <.0001 | |
| item4 | Difficulty | -1.09577 | 0.07727 | <.0001 |
| Slope | 1.86821 | 0.20452 | <.0001 | |
| item5 | Difficulty | -1.07857 | 0.07784 | <.0001 |
| Slope | 1.78392 | 0.19080 | <.0001 | |
| item6 | Difficulty | -0.95057 | 0.09377 | <.0001 |
| Slope | 1.04203 | 0.10284 | <.0001 | |
| item7 | Difficulty | -0.65085 | 0.06918 | <.0001 |
| Slope | 1.45413 | 0.13473 | <.0001 | |
| item8 | Difficulty | -0.76372 | 0.07583 | <.0001 |
| Slope | 1.30444 | 0.12230 | <.0001 | |
| item9 | Difficulty | -0.72281 | 0.07030 | <.0001 |
| Slope | 1.50740 | 0.14242 | <.0001 | |
| item10 | Difficulty | -0.50750 | 0.06091 | <.0001 |
| Slope | 1.82387 | 0.17155 | <.0001 | |
| item11 | Difficulty | -0.01360 | 0.06433 | 0.4163 |
| Slope | 1.26234 | 0.11287 | <.0001 | |
| item12 | Difficulty | 0.04013 | 0.05537 | 0.2343 |
| Slope | 2.02257 | 0.20099 | <.0001 | |
| item13 | Difficulty | 0.16034 | 0.06845 | 0.0096 |
| Slope | 1.13120 | 0.10199 | <.0001 | |
| item14 | Difficulty | 0.01069 | 0.05625 | 0.4246 |
| Slope | 1.89082 | 0.18128 | <.0001 | |
| item15 | Difficulty | 0.07152 | 0.07328 | 0.1645 |
| Slope | 0.96388 | 0.09050 | <.0001 | |
| item16 | Difficulty | -0.81412 | 0.07905 | <.0001 |
| Slope | 1.25375 | 0.11885 | <.0001 | |
| item17 | Difficulty | -0.92046 | 0.09289 | <.0001 |
| Slope | 1.02930 | 0.10125 | <.0001 | |
| item18 | Difficulty | -0.59407 | 0.06606 | <.0001 |
| Slope | 1.58443 | 0.14868 | <.0001 | |
| item19 | Difficulty | -0.97598 | 0.09743 | <.0001 |
| Slope | 0.97979 | 0.09761 | <.0001 | |
| item20 | Difficulty | -0.48859 | 0.05960 | <.0001 |
| Slope | 1.95710 | 0.18827 | <.0001 | |
| item21 | Difficulty | -0.60655 | 0.06819 | <.0001 |
| Slope | 1.45324 | 0.13427 | <.0001 | |
| item22 | Difficulty | -0.51263 | 0.06188 | <.0001 |
| Slope | 1.74472 | 0.16251 | <.0001 | |
| item23 | Difficulty | -0.90928 | 0.08451 | <.0001 |
| Slope | 1.20281 | 0.11623 | <.0001 | |
| item24 | Difficulty | -0.56515 | 0.06295 | <.0001 |
| Slope | 1.74437 | 0.16384 | <.0001 | |
| item25 | Difficulty | -0.58905 | 0.06718 | <.0001 |
| Slope | 1.48957 | 0.13785 | <.0001 | |
Output 53.1.9: The Difficulty Parameter SAS Data Set
| Obs | Item | Difficulty |
|---|---|---|
| 1 | item1 | -1.32543 |
| 2 | item2 | -0.99702 |
| 3 | item3 | -1.24965 |
| 4 | item4 | -1.09577 |
| 5 | item5 | -1.07857 |
| 6 | item6 | -0.95057 |
| 7 | item7 | -0.65085 |
| 8 | item8 | -0.76372 |
| 9 | item9 | -0.72281 |
| 10 | item10 | -0.50750 |
| 11 | item11 | -0.01360 |
| 12 | item12 | 0.04013 |
| 13 | item13 | 0.16034 |
| 14 | item14 | 0.01069 |
| 15 | item15 | 0.07152 |
| 16 | item16 | -0.81412 |
| 17 | item17 | -0.92046 |
| 18 | item18 | -0.59407 |
| 19 | item19 | -0.97598 |
| 20 | item20 | -0.48859 |
| 21 | item21 | -0.60655 |
| 22 | item22 | -0.51263 |
| 23 | item23 | -0.90928 |
| 24 | item24 | -0.56515 |
| 25 | item25 | -0.58905 |
Then you save the estimates of slopes and difficulties in the data set ParmEst and create two separate data sets to store the difficulty and slope parameters:
data Diffs(keep=Item Difficulty); set ParmEst; Difficulty = Estimate; if (Parameter = "Difficulty") then output; run; proc print data=Diffs; run;
data Slopes(keep=Item Slope); set ParmEst; Slope = Estimate; if (Parameter = "Slope") then output; run; proc print data=Slopes; run;
The two SAS data sets are shown in Output 53.1.9 and Output 53.1.10.
Output 53.1.10: The Slope Parameter SAS Data Set
| Obs | Item | Slope |
|---|---|---|
| 1 | item1 | 1.44263 |
| 2 | item2 | 1.82221 |
| 3 | item3 | 1.58762 |
| 4 | item4 | 1.86821 |
| 5 | item5 | 1.78392 |
| 6 | item6 | 1.04203 |
| 7 | item7 | 1.45413 |
| 8 | item8 | 1.30444 |
| 9 | item9 | 1.50740 |
| 10 | item10 | 1.82387 |
| 11 | item11 | 1.26234 |
| 12 | item12 | 2.02257 |
| 13 | item13 | 1.13120 |
| 14 | item14 | 1.89082 |
| 15 | item15 | 0.96388 |
| 16 | item16 | 1.25375 |
| 17 | item17 | 1.02930 |
| 18 | item18 | 1.58443 |
| 19 | item19 | 0.97979 |
| 20 | item20 | 1.95710 |
| 21 | item21 | 1.45324 |
| 22 | item22 | 1.74472 |
| 23 | item23 | 1.20281 |
| 24 | item24 | 1.74437 |
| 25 | item25 | 1.48957 |
Now you can use PROC SORT to sort the items by either difficulty or slope as follows:
proc sort data=Diffs; by Difficulty; run; proc print data=Diffs; run;
proc sort data=Slopes; by Slope; run; proc print data=Slopes; run;
Output 53.1.11 and Output 53.1.12 show the sorted data sets.
Output 53.1.11: Items Sorted by Difficulty
| Obs | Item | Difficulty |
|---|---|---|
| 1 | item1 | -1.32543 |
| 2 | item3 | -1.24965 |
| 3 | item4 | -1.09577 |
| 4 | item5 | -1.07857 |
| 5 | item2 | -0.99702 |
| 6 | item19 | -0.97598 |
| 7 | item6 | -0.95057 |
| 8 | item17 | -0.92046 |
| 9 | item23 | -0.90928 |
| 10 | item16 | -0.81412 |
| 11 | item8 | -0.76372 |
| 12 | item9 | -0.72281 |
| 13 | item7 | -0.65085 |
| 14 | item21 | -0.60655 |
| 15 | item18 | -0.59407 |
| 16 | item25 | -0.58905 |
| 17 | item24 | -0.56515 |
| 18 | item22 | -0.51263 |
| 19 | item10 | -0.50750 |
| 20 | item20 | -0.48859 |
| 21 | item11 | -0.01360 |
| 22 | item14 | 0.01069 |
| 23 | item12 | 0.04013 |
| 24 | item15 | 0.07152 |
| 25 | item13 | 0.16034 |
Output 53.1.12: Items Sorted by Slope
| Obs | Item | Slope |
|---|---|---|
| 1 | item15 | 0.96388 |
| 2 | item19 | 0.97979 |
| 3 | item17 | 1.02930 |
| 4 | item6 | 1.04203 |
| 5 | item13 | 1.13120 |
| 6 | item23 | 1.20281 |
| 7 | item16 | 1.25375 |
| 8 | item11 | 1.26234 |
| 9 | item8 | 1.30444 |
| 10 | item1 | 1.44263 |
| 11 | item21 | 1.45324 |
| 12 | item7 | 1.45413 |
| 13 | item25 | 1.48957 |
| 14 | item9 | 1.50740 |
| 15 | item18 | 1.58443 |
| 16 | item3 | 1.58762 |
| 17 | item24 | 1.74437 |
| 18 | item22 | 1.74472 |
| 19 | item5 | 1.78392 |
| 20 | item2 | 1.82221 |
| 21 | item10 | 1.82387 |
| 22 | item4 | 1.86821 |
| 23 | item14 | 1.89082 |
| 24 | item20 | 1.95710 |
| 25 | item12 | 2.02257 |
Notice that the sorting does not work correctly if any of the items have more than one threshold (ordinal response) or slope (multidimensional model).
Now, suppose you want to group the items into subgroups based on their difficulty parameters and then sort the items in each
subgroup by their slope parameters. First, you need to merge the two data sets, Diffs and Slopes, into one data set. Then, you add another variable, called DiffLevel, to indicate the subgroups. The following statements show these steps:
proc sort data=Slopes; by Item; run; proc sort data=Diffs; by Item; run; data ItemEst; merge Diffs Slopes; by Item; if Difficulty < -1.0 then DiffLevel = 1; else if Difficulty < 0 then DiffLevel = 2; else if Difficulty < 1 then DiffLevel = 3; else DiffLevel = 4; run; proc print data=ItemEst; run;
Output 53.1.13 shows the merged data set.
Output 53.1.13: The Merged SAS Data Set
| Obs | Item | Difficulty | Slope | DiffLevel |
|---|---|---|---|---|
| 1 | item1 | -1.32543 | 1.44263 | 1 |
| 2 | item10 | -0.50750 | 1.82387 | 2 |
| 3 | item11 | -0.01360 | 1.26234 | 2 |
| 4 | item12 | 0.04013 | 2.02257 | 3 |
| 5 | item13 | 0.16034 | 1.13120 | 3 |
| 6 | item14 | 0.01069 | 1.89082 | 3 |
| 7 | item15 | 0.07152 | 0.96388 | 3 |
| 8 | item16 | -0.81412 | 1.25375 | 2 |
| 9 | item17 | -0.92046 | 1.02930 | 2 |
| 10 | item18 | -0.59407 | 1.58443 | 2 |
| 11 | item19 | -0.97598 | 0.97979 | 2 |
| 12 | item2 | -0.99702 | 1.82221 | 2 |
| 13 | item20 | -0.48859 | 1.95710 | 2 |
| 14 | item21 | -0.60655 | 1.45324 | 2 |
| 15 | item22 | -0.51263 | 1.74472 | 2 |
| 16 | item23 | -0.90928 | 1.20281 | 2 |
| 17 | item24 | -0.56515 | 1.74437 | 2 |
| 18 | item25 | -0.58905 | 1.48957 | 2 |
| 19 | item3 | -1.24965 | 1.58762 | 1 |
| 20 | item4 | -1.09577 | 1.86821 | 1 |
| 21 | item5 | -1.07857 | 1.78392 | 1 |
| 22 | item6 | -0.95057 | 1.04203 | 2 |
| 23 | item7 | -0.65085 | 1.45413 | 2 |
| 24 | item8 | -0.76372 | 1.30444 | 2 |
| 25 | item9 | -0.72281 | 1.50740 | 2 |
Then, you can sort the items by slope within each difficulty group as follows:
proc sort data=ItemEst; by difflevel slope; run; proc print data=ItemEst; run;
Output 53.1.14 shows the data set after sorting.
Output 53.1.14: Item Sorted by Slope within Each Difficulty Group
| Obs | Item | Difficulty | Slope | DiffLevel |
|---|---|---|---|---|
| 1 | item1 | -1.32543 | 1.44263 | 1 |
| 2 | item3 | -1.24965 | 1.58762 | 1 |
| 3 | item5 | -1.07857 | 1.78392 | 1 |
| 4 | item4 | -1.09577 | 1.86821 | 1 |
| 5 | item19 | -0.97598 | 0.97979 | 2 |
| 6 | item17 | -0.92046 | 1.02930 | 2 |
| 7 | item6 | -0.95057 | 1.04203 | 2 |
| 8 | item23 | -0.90928 | 1.20281 | 2 |
| 9 | item16 | -0.81412 | 1.25375 | 2 |
| 10 | item11 | -0.01360 | 1.26234 | 2 |
| 11 | item8 | -0.76372 | 1.30444 | 2 |
| 12 | item21 | -0.60655 | 1.45324 | 2 |
| 13 | item7 | -0.65085 | 1.45413 | 2 |
| 14 | item25 | -0.58905 | 1.48957 | 2 |
| 15 | item9 | -0.72281 | 1.50740 | 2 |
| 16 | item18 | -0.59407 | 1.58443 | 2 |
| 17 | item24 | -0.56515 | 1.74437 | 2 |
| 18 | item22 | -0.51263 | 1.74472 | 2 |
| 19 | item2 | -0.99702 | 1.82221 | 2 |
| 20 | item10 | -0.50750 | 1.82387 | 2 |
| 21 | item20 | -0.48859 | 1.95710 | 2 |
| 22 | item15 | 0.07152 | 0.96388 | 3 |
| 23 | item13 | 0.16034 | 1.13120 | 3 |
| 24 | item14 | 0.01069 | 1.89082 | 3 |
| 25 | item12 | 0.04013 | 2.02257 | 3 |