The X12 Procedure
- Overview
-
Getting Started

-
SyntaxFunctional SummaryPROC X12 StatementADJUST StatementARIMA StatementAUTOMDL StatementBY StatementCHECK StatementESTIMATE StatementEVENT StatementFORECAST StatementID StatementIDENTIFY StatementINPUT StatementOUTLIER StatementOUTPUT StatementPICKMDL StatementREGRESSION StatementSEATSDECOMP StatementTABLES StatementTRANSFORM StatementUSERDEFINED StatementVAR StatementX11 Statement
-
DetailsData RequirementsMissing ValuesSAS Predefined EventsUser-Defined Regression VariablesCombined Test for the Presence of Identifiable SeasonalityComputationsPICKMDL Model SelectionSEATS DecompositionDisplayed Output, ODS Table Names, and OUTPUT Tablename KeywordsUsing Auxiliary Variables to Subset Output Data SetsODS GraphicsOUT= Data SetSEATSDECOMP OUT= Data SetSpecial Data Sets
-
ExamplesARIMA Model IdentificationModel EstimationSeasonal AdjustmentRegARIMA Automatic Model SelectionAutomatic Outlier DetectionUser-Defined RegressorsMDLINFOIN= and MDLINFOOUT= Data SetsSetting Regression ParametersCreating an MDLINFO= Data Set for Use with the PICKMDL StatementIllustration of ODS GraphicsAUXDATA= Data Set
- References
Special Data Sets
The X12 procedure can input the MDLINFOIN= and output the MDLINFOOUT= data sets. The structure of both of these data sets is the same. The difference is that when the MDLINFOIN= data set is read, only information relative to specifying a model is processed, whereas the MDLINFOOUT= data set contains the results of estimating a model. The X12 procedure can also read data sets that contain event definition data. The structure of these data sets is the same as in the SAS® High Performance Forecasting system.
MDLINFOIN= and MDLINFOOUT= Data Sets
The MDLINFOIN= and MDLINFOOUT= data sets can contain the following variables:
- BY variables
-
enable the model information to be specified by BY groups. BY variables can be included in this data set that match the BY variables used to process the series. If no BY variables are included, then the models specified by
_NAME_in the MDLINFOIN= data set apply to all BY groups in the DATA= data set. - _NAME_
-
should contain the variable name of the time series to which a particular model is to be applied. Omit the
_NAME_variable if you are specifying the same model for all series in a BY group. - _MODELTYPE_
-
specifies whether the observation contains regression or ARIMA information. The value of
_MODELTYPE_should be either REG to supply regression information or ARIMA to supply model information. If valid regression information exists in the MDLINFOIN= data set for a BY group and series being processed, then the REGRESSION, INPUT, and EVENT statements are ignored for that BY group and series. Likewise, if valid ARIMA model information exists in the data set, then the AUTOMDL, ARIMA, and TRANSFORM statements are ignored. Valid values for the other variables in the data set depend on the value of the_MODELTYPE_variable. Although other values of_MODELTYPE_might be permitted in other SAS procedures, PROC X12 recognizes only REG and ARIMA. - _MODELPART_
-
further qualifies the regression information in the observation. For
_MODELTYPE_=REG, valid values of_MODELPART_are INPUT, EVENT, and PREDEFINED. A value of INPUT indicates that this observation refers to the user-defined variable whose name is given in_DSVAR_. Likewise, a value of EVENT indicates that the observation refers to the SAS or user-defined event whose name is given in_DSVAR_. PREDEFINED indicates that the name given in_DSVAR_is a predefined U.S. Census Bureau variable. If only ARIMA model information is included in the data set (that is, all observations have_MODELTYPE_=ARIMA), then the_MODELPART_variable can be omitted. For observations where_MODELTYPE_=ARIMA, valid values for_MODELPART_are FORECAST, “.”, or blank. - _COMPONENT_
-
further qualifies the regression or ARIMA information in the observation. For
_MODELTYPE_=REG, the only valid value of_COMPONENT_is SCALE. For_MODELTYPE_=ARIMA, the valid values of_COMPONENT_are TRANSFORM, CONSTANT, NONSEASONAL, and SEASONAL. TRANSFORM indicates that the observation contains the information that would be supplied in the TRANSFORM statement. CONSTANT is specified to control the constant term in the model. NONSEASONAL and SEASONAL refer to the AR, MA, and differencing terms in the ARIMA model. - _PARMTYPE_
-
further qualifies the regression or ARIMA information in the observation. For
_MODELTYPE_=REG, the value of_PARMTYPE_is the same as the value of the USERTYPE= option in the REGRESSION statement. Since the USERTYPE= option applies only to user-defined events and variables, the value of_PARMTYPE_does not alter processing in observations where_MODELPART_=PREDEFINED. However, it is consistent to use a value for_PARMTYPE_that matches the U.S. Census Bureau predefined variable. For the constant term in the model information,_PARMTYPE_should be SCALE. For transformation information, the value of_PARMTYPE_should be NONE, LOG, LOGIT, SQRT, or BOXCOX. For_MODELTYPE_=ARIMA, valid values of_PARMTYPE_are AR, MA, and DIF. - _DSVAR_
-
specifies the variable name associated with the current observation. For
_MODELTYPE_=REG, the value of_DSVAR_is the name of the user-defined variable, the event, or the U.S. Census Bureau predefined variable. For_MODELTYPE_=ARIMA,_DSVAR_should match the name of the series being processed. If the ARIMA model information applies to more than one series, then_DSVAR_can be blank or “.”, equivalently. - _VALUE_
-
contains a numerical value that is used as a parameter for certain types of information. For example, the PREDEFINED=EASTER(6) option in the REGESSION statement is implemented in the MDLINFOIN= data set by using
_DSVAR_=EASTERand_VALUE_=6. For a BOXCOX transformation,_VALUE_is set equal to the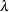 parameter value. For
parameter value. For _COMPONENT_=SEASONAL, if_VALUE_is nonmissing, then_VALUE_is used as the seasonal period. If_VALUE_is missing for_COMPONENT_=SEASONAL, then the seasonal period is determined by the interval of the series. - _FACTOR_
-
applies only to the AR and MA portions of the ARIMA model. The value of
_FACTOR_identifies the factor of the given AR or MA term. Therefore, the value of_FACTOR_is the same for all observations that are related to the same factor. - _LAG_
-
identifies the degree for differencing and AR and MA lags. If
_COMPONENT_=SEASONAL, then the value in_LAG_is multiplied by the seasonal period indicated by the value of_VALUE_. - _SHIFT_
-
contains the shift value for transfer functions. This value is not processed by PROC X12, but it might be processed by other procedures in which transfer functions can be specified.
- _NOEST_
-
indicates whether a parameter associated with the observation is to be estimated. For example, the NOINT option is indicated by
_COMPONENT_=CONSTANTwith_NOEST_=1and_EST_=0._NOEST_=1indicates that the value in_EST_is a fixed value._NOEST_pertains to the constant term, to AR and MA parameters, and to regression parameters. - _EST_
-
contains an initial or fixed value for a parameter associated with the observation that is to be estimated.
_NOEST_=1indicates the value in_EST_is a fixed value. _EST_ pertains to the constant term, to AR and MA parameters, and to regression parameters. - _STDERR_
-
contains output information about estimated parameters. The variable
_STDERR_is not processed by the MDLINFOIN= data set for PROC X12. In the MDLINFOOUT= data set,_STDERR_contains the standard error that pertains to the estimated parameter in the variable_EST_. - _TVALUE_
-
contains output information about estimated parameters. The variable
_TVALUE_is not processed by the MDLINFOIN= data set for PROC X12. In the MDLINFOOUT= data set,_TVALUE_contains the t value that pertains to the estimated parameter in the variable_EST_. - _PVALUE_
-
contains output information about estimated parameters. The variable
_PVALUE_is not processed by the MDLINFOIN= data set for PROC X12. In the MDLINFOOUT= data set,_PVALUE_contains the p-value that pertains to the estimated parameter in the variable_EST_.
INEVENT= Data Set
The INEVENT= data set can contain the following variables. When a variable is omitted from the data set, that variable is assumed to have the default value for all observations. The default values are specified in the list.
- _NAME_
-
specifies the event variable name.
_NAME_is displayed with the case preserved. Since_NAME_is a SAS variable name, the event can be referenced by using any case. The_NAME_variable is required; there is no default. - _CLASS_
-
specifies the class of event: SIMPLE, COMBINATION, PREDEFINED. The default for
_CLASS_is SIMPLE. - _KEYNAME_
-
contains either a date keyword (SIMPLE EVENT), a predefined event variable name (PREDEFINED EVENT), or an event name (COMBINATION EVENT). All
_KEYNAME_values are displayed in upper case. However, if the_KEYNAME_value refers to an event name, then the actual name can be of mixed case. The default for_KEYNAME_is no keyname, designated by “.”. - _STARTDATE_
-
contains either the date timing value or the first date timing value to use in a do-list. The default for
_STARTDATE_is no date, designated by a missing value. - _ENDDATE_
-
contains the last date timing value to use in a do-list. The default for
_ENDDATE_is no date, designated by a missing value. - _DATEINTRVL_
-
contains the interval for the date do-list. The default for _DATEINTRVL_ is no interval, designated by “.”.
- _STARTDT_
-
contains either the datetime timing value or the first datetime timing value to use in a do-list. The default for
_STARTDT_is no datetime, designated by a missing value. - _ENDDT_
-
contains the last datetime timing value to use in a do-list. The default for _ENDDT_ is no datetime, designated by a missing value.
- _DTINTRVL_
-
contains the interval for the datetime do-list. The default for
_DTINTRVL_is no interval, designated by “.”. - _STARTOBS_
-
contains either the observation number timing value or the first observation number timing value to use in a do-list. The default for
_STARTOBS_is no observation number, designated by a missing value. - _ENDOBS_
-
contains the last observation number timing value to use in a do-list. The default for
_ENDOBS_is no observation number, designated by a missing value. - _OBSINTRVL_
-
contains the interval length of the observation number do-list. The default for
_OBSINTRVL_is no interval, designated by “.”. - _TYPE_
-
specifies the type of event. The valid values of
_TYPE_are POINT, LS, RAMP, TR, TEMPRAMP, TC, LIN, LINEAR, QUAD, CUBIC, INV, INVERSE, LOG, and LOGARITHMIC. The default for_TYPE_is POINT. - _VALUE_
-
specifies the value for nonzero observation. The default for
_VALUE_is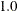 .
.
- _PULSE_
-
specifies the interval that defines the units for the duration values. The default for
_PULSE_is no interval, designated by “.”. - _DUR_BEFORE_
-
specifies the number of durations before the timing value. The default for
_DUR_BEFORE_is 0. - _DUR_AFTER_
-
specifies the number of durations after the timing value. The default for
_DUR_AFTER_is 0. - _SLOPE_BEF_
-
determines whether the curve is GROWTH or DECAY before the timing value for
_TYPE_=RAMP,_TYPE_=TEMPRAMP, and_TYPE_=TC. Valid values are GROWTH and DECAY. The default for_SLOPE_BEF_is GROWTH. - _SLOPE_AFT_
-
determines whether the curve is GROWTH or DECAY after the timing value for
_TYPE_=RAMP,_TYPE_=TEMPRAMP, and_TYPE_=TC. Valid values are GROWTH and DECAY. The default for_SLOPE_AFT_is GROWTH unless_TYPE_=TC; then the default is DECAY. - _SHIFT_
-
specifies the number of
_PULSE_= intervals to shift the timing value. The shift can be positive (forward in time) or negative (backward in time). If_PULSE_= is not specified, then the shift is in observations. The default for_SHIFT_is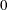 .
.
- _TCPARM_
-
specifies the parameter for EVENT of TYPE=TC. The default for
_TCPARM_is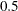 .
.
- _RULE_
-
specifies the rule to use when combining events or when timing values of an event overlap. The valid values of
_RULE_are ADD, MAX, MIN, MINNZ, MINMAG, and MULT. The default for_RULE_is ADD. - _PERIOD_
-
specifies the frequency interval at which the event should be repeated. If this value is missing, then the event is not periodic. The default for
_PERIOD_is no interval, designated by “.”. - _LABEL_
-
specifies the label or description for the event. If a label is not specified, then the default label value is displayed as “.”. For events that produce dummy variables, either the user-supplied label or the default label is used. For COMPLEX events, the
_LABEL_value is merely a description of the group of events.
OUTSTAT= Data Set
The OUTSTAT= data set can contain the following variables:
- BY variables
-
sorts the statistics into BY groups. BY variables are included in this data set that match the BY variables used to process the series.
- NAME
-
specifies the variable name of the time series to which the statistics apply.
- STAT
-
describes the statistic that is stored in
VALUEorCVALUE.STATtakes on the following values:- Period
-
the period of the series, 4 or 12.
- Mode
-
the mode of the seasonal adjustment from the X11 statement. Possible values are ADD, MULT, LOGADD, and PSEUDOADD.
- Start
-
the beginning of the model span expressed as monyyyy for monthly series or yyyyQq for quarterly series.
- End
-
the end of the model span expressed as monyyyy for monthly series or yyyyQq for quarterly series.
- NbFcst
-
the number of forecast observations.
- SigmaLimLower
-
the lower sigma limit in standard deviation units.
- SigmaLimUpper
-
the upper sigma limit in standard deviation units.
- pLBQ_24
-
the Ljung-Box Q statistic of the residuals at lag 24, for monthly series. Note that lag 12 (pLBQ_12) and lag 16 (pLBQ_16) are included in the data set for quarterly series.
- D8Fs
-
the stable seasonality F test value from Table D8.
- D8Fm
-
the moving seasonality F test value from Table D8.
- ISRatio
-
the final irregular-to-seasonal ratio from Table F 2.H.
- SMA_ALL
-
the final seasonal moving average filter for all periods.
- RSF
-
the residual seasonality F test value for Table D11 for the entire series.
- RSF3
-
the residual seasonality F test value for Table D11 for the last three years.
- RSFA
-
the residual seasonality F test value for Table D11.A for the entire series.
- RSF3A
-
the residual seasonality F test value for Table D11.A for the last three years.
- RSFR
-
the residual seasonality F test value for Table D11.R for the entire series.
- RSF3R
-
the residual seasonality F test value for Table D11.R for the last three years.
- TMA
-
the Henderson trend moving average filter selected.
- ICRatio
-
the final irregular-to-trend cycle ratio from Table F 2.H.
- E5sd
-
the standard deviation from Table E5.
- E6sd
-
the standard deviation from Table E6.
- E6Asd
-
the standard deviation from Table E6.A.
- MCD
-
months of cyclical dominance.
- Q
-
the overall level Q from Table F3.
- Q2
-
Q overall level without M2 from Table F3.
- FMT
-
indicates whether the format is numeric or character.
FMT=“NUM” if the value is numeric and stored in theVALUEvariable.FMT=“CHAR” if the value is a string and stored in theCVALUEvariable. - VALUE
-
contains the numerical value of the statistic or missing if the statistic is of type character.
- CVALUE
-
contains the character value of the text statistic or blank if the statistic is of type numeric.