The ARIMA Procedure
- Overview
-
Getting Started
 The Three Stages of ARIMA ModelingIdentification StageEstimation and Diagnostic Checking StageForecasting StageUsing ARIMA Procedure StatementsGeneral Notation for ARIMA ModelsStationarityDifferencingSubset, Seasonal, and Factored ARMA ModelsInput Variables and Regression with ARMA ErrorsIntervention Models and Interrupted Time SeriesRational Transfer Functions and Distributed Lag ModelsForecasting with Input VariablesData Requirements
The Three Stages of ARIMA ModelingIdentification StageEstimation and Diagnostic Checking StageForecasting StageUsing ARIMA Procedure StatementsGeneral Notation for ARIMA ModelsStationarityDifferencingSubset, Seasonal, and Factored ARMA ModelsInput Variables and Regression with ARMA ErrorsIntervention Models and Interrupted Time SeriesRational Transfer Functions and Distributed Lag ModelsForecasting with Input VariablesData Requirements -
Syntax
-
DetailsThe Inverse Autocorrelation FunctionThe Partial Autocorrelation FunctionThe Cross-Correlation FunctionThe ESACF MethodThe MINIC MethodThe SCAN MethodStationarity TestsPrewhiteningIdentifying Transfer Function ModelsMissing Values and AutocorrelationsEstimation DetailsSpecifying Inputs and Transfer FunctionsInitial ValuesStationarity and InvertibilityNaming of Model ParametersMissing Values and Estimation and ForecastingForecasting DetailsForecasting Log Transformed DataSpecifying Series PeriodicityDetecting OutliersOUT= Data SetOUTCOV= Data SetOUTEST= Data SetOUTMODEL= SAS Data SetOUTSTAT= Data SetPrinted OutputODS Table NamesStatistical Graphics
-
Examples
- References
The ESTIMATE statement specifies an ARMA model or transfer function model for the response variable specified in the previous IDENTIFY statement, and produces estimates of its parameters. The ESTIMATE statement also prints diagnostic information by which to check the model. The label in the ESTIMATE statement is optional. Include an ESTIMATE statement for each model that you want to estimate.
Options used in the ESTIMATE statement are described in the following sections.
The following options are used to define the model to be estimated and to control the output that is printed.
- ALTPARM
-
specifies the alternative parameterization of the overall scale of transfer functions in the model. See the section Alternative Model Parameterization for details.
-
INPUT=variable
INPUT=( transfer-function variable …) -
specifies input variables and their transfer functions.
The variables used on the INPUT= option must be included in the CROSSCORR= list in the previous IDENTIFY statement. If any differencing is specified in the CROSSCORR= list, then the differenced series is used as the input to the transfer function.
The transfer function specification for an input variable is optional. If no transfer function is specified, the input variable enters the model as a simple regressor. If specified, the transfer function specification has the following syntax:
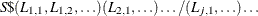
Here, S is a shift or lag of the input variable, the terms before the slash (/) are numerator factors, and the terms after the slash (/) are denominator factors of the transfer function. All three parts are optional. See the section Specifying Inputs and Transfer Functions for details.
- METHOD=value
-
specifies the estimation method to use. METHOD=ML specifies the maximum likelihood method. METHOD=ULS specifies the unconditional least squares method. METHOD=CLS specifies the conditional least squares method. METHOD=CLS is the default. See the section Estimation Details for more information.
- NOCONSTANT
- NOINT
-
suppresses the fitting of a constant (or intercept) parameter in the model. (That is, the parameter
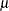 is omitted.)
is omitted.)
- NODF
-
estimates the variance by dividing the error sum of squares (SSE) by the number of residuals. The default is to divide the SSE by the number of residuals minus the number of free parameters in the model.
- NOPRINT
-
suppresses the normal printout generated by the ESTIMATE statement. If the NOPRINT option is specified for the ESTIMATE statement, then any error and warning messages are printed to the SAS log.
-
P=order
P=(lag, …, lag ) …(lag, …, lag ) -
specifies the autoregressive part of the model. By default, no autoregressive parameters are fit.
P=(l
 , l
, l  , …, l
, …, l  ) defines a model with autoregressive parameters at the specified lags. P= order is equivalent to P=(1, 2, …, order).
) defines a model with autoregressive parameters at the specified lags. P= order is equivalent to P=(1, 2, …, order).
A concatenation of parenthesized lists specifies a factored model. For example, P=(1,2,5)(6,12) specifies the autoregressive model
![\[ (1-{\phi }_{1,1}{B}-{\phi }_{1,2}{B}^{2}- {\phi }_{1,3}{B}^{5}) (1-{\phi }_{2,1}{B}^{6} -{\phi }_{2,2}{B}^{12}) \]](images/etsug_arima0077.png)
- PLOT
-
plots the residual autocorrelation functions. The sample autocorrelation, the sample inverse autocorrelation, and the sample partial autocorrelation functions of the model residuals are plotted.
-
Q=order
Q=(lag, …, lag ) …(lag, …, lag ) -
specifies the moving-average part of the model. By default, no moving-average part is included in the model.
Q=(l
, l , …, l  ) defines a model with moving-average parameters at the specified lags. Q= order is equivalent to Q=(1, 2, …, order). A concatenation of parenthesized lists specifies a factored model. The interpretation of factors and lags is the same as
for the P= option.
) defines a model with moving-average parameters at the specified lags. Q= order is equivalent to Q=(1, 2, …, order). A concatenation of parenthesized lists specifies a factored model. The interpretation of factors and lags is the same as
for the P= option.
- WHITENOISE=ST | IGNOREMISS
-
specifies the type of test statistic that is used in the white noise test of the series when the series contains missing values. If WHITENOISE=IGNOREMISS, the standard Ljung-Box test statistic is used. If WHITENOISE=ST, a modification of this statistic suggested by Stoffer and Toloi (1992) is used. The default is WHITENOISE=ST.
The following options enable you to specify values for the model parameters. These options can provide starting values for the estimation process, or you can specify fixed parameters for use in the FORECAST stage and suppress the estimation process with the NOEST option. By default, the ARIMA procedure finds initial parameter estimates and uses these estimates as starting values in the iterative estimation process.
If values for any parameters are specified, values for all parameters should be given. The number of values given must agree with the model specifications.
The following options can be used to control the iterative process of minimizing the error sum of squares or maximizing the log-likelihood function. These tuning options are not usually needed but can be useful if convergence problems arise.
-
BACKLIM=
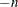
-
omits the specified number of initial residuals from the sum of squares or likelihood function. Omitting values can be useful for suppressing transients in transfer function models that are sensitive to start-up values.
- CONVERGE=value
-
specifies the convergence criterion. Convergence is assumed when the largest change in the estimate for any parameter is less that the CONVERGE= option value. If the absolute value of the parameter estimate is greater than 0.01, the relative change is used; otherwise, the absolute change in the estimate is used. The default is CONVERGE=0.001.
- DELTA=value
-
specifies the perturbation value for computing numerical derivatives. The default is DELTA=0.001.
- GRID
-
prints the error sum of squares (SSE) or concentrated log-likelihood surface in a small grid of the parameter space around the final estimates. For each pair of parameters, the SSE is printed for the nine parameter-value combinations formed by the grid, with a center at the final estimates and with spacing given by the GRIDVAL= specification. The GRID option can help you judge whether the estimates are truly at the optimum, since the estimation process does not always converge. For models with a large number of parameters, the GRID option produces voluminous output.
- GRIDVAL=number
-
controls the spacing in the grid printed by the GRID option. The default is GRIDVAL=0.005.
-
MAXITER=n
MAXIT=n -
specifies the maximum number of iterations allowed. The default is MAXITER=50.
- NOLS
-
begins the maximum likelihood or unconditional least squares iterations from the preliminary estimates rather than from the conditional least squares estimates that are produced after four iterations. See the section Estimation Details for more information.
- NOSTABLE
-
specifies that the autoregressive and moving-average parameter estimates for the noise part of the model not be restricted to the stationary and invertible regions, respectively. See the section Stationarity and Invertibility for more information.
- PRINTALL
-
prints preliminary estimation results and the iterations in the final estimation process.
- NOTFSTABLE
-
specifies that the parameter estimates for the denominator polynomial of the transfer function part of the model not be restricted to the stability region. See the section Stationarity and Invertibility for more information.
- SINGULAR=value
-
specifies the criterion for checking singularity. If a pivot of a sweep operation is less than the SINGULAR= value, the matrix is deemed singular. Sweep operations are performed on the Jacobian matrix during final estimation and on the covariance matrix when preliminary estimates are obtained. The default is SINGULAR=1E–7.