The OPTNET Procedure
- Overview
-
Getting Started

-
SyntaxFunctional SummaryPROC OPTNET StatementBICONCOMP StatementCLIQUE StatementCONCOMP StatementCYCLE StatementDATA_LINKS_VAR StatementDATA_MATRIX_VAR StatementDATA_NODES_VAR StatementLINEAR_ASSIGNMENT StatementMINCOSTFLOW StatementMINCUT StatementMINSPANTREE StatementSHORTPATH StatementTRANSITIVE_CLOSURE StatementTSP Statement
-
Details
-
ExamplesArticulation Points in a Terrorist NetworkCycle Detection for Kidney Donor ExchangeLinear Assignment Problem for Minimizing Swim TimesLinear Assignment Problem, Sparse Format versus Dense FormatMinimum Spanning Tree for Computer Network TopologyTransitive Closure for Identification of Circular Dependencies in a Bug Tracking SystemTraveling Salesman Tour through US Capital Cities
- References
This section describes how to input a graph for analysis by PROC OPTNET. Let ![]() define a graph with a set
define a graph with a set ![]() of nodes and a set
of nodes and a set ![]() of links.
of links.
Consider the directed graph shown in Figure 2.5.
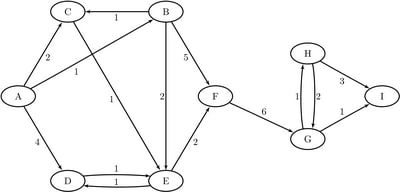
Notice that each node and link has associated attributes: a node label and a link weight.
The DATA_LINKS= option in the PROC OPTNET statement defines the data set that contains the list of links in the graph. A link is represented as a pair of nodes, which are defined by using either numeric or character labels. The links data set is expected to contain some combination of the following possible variables:
-
from: the from node (this variable can be numeric or character) -
to: the to node (this variable can be numeric or character) -
weight: the link weight (this variable must be numeric) -
lower: the link flow lower bound (this variable must be numeric) -
upper: the link flow upper bound (this variable must be numeric)
As described in the GRAPH_DIRECTION= option, if the graph is undirected, the from and to labels are interchangeable. If the weights are not given for algorithms that call for link weights, they are all assumed to be 1.
The data set variable names can have any values that you want. If you use nonstandard names, you must identify the variables by using the DATA_LINKS_VAR statement, as described in the section DATA_LINKS_VAR Statement.
For example, the following two data sets identify the same graph:
data LinkSetInA; input from $ to $ weight; datalines; A B 1 A C 2 A D 4 ; data LinkSetInB; input source_node $ sink_node $ value; datalines; A B 1 A C 2 A D 4 ;
These data sets can be presented to PROC OPTNET by using the following equivalent statements:
proc optnet
data_links = LinkSetInA;
run;
proc optnet
data_links = LinkSetInB;
data_links_var
from = source_node
to = sink_node
weight = value;
run;
The directed graph ![]() shown in Figure 2.5 can be represented by the following links data set
shown in Figure 2.5 can be represented by the following links data set LinkSetIn:
data LinkSetIn; input from $ to $ weight @@; datalines; A B 1 A C 2 A D 4 B C 1 B E 2 B F 5 C E 1 D E 1 E D 1 E F 2 F G 6 G H 1 G I 1 H G 2 H I 3 ;
The following statements read in this graph, declare it as a directed graph, and output the resulting links and nodes data sets. These statements do not run any algorithms, so the resulting output contains only the input graph.
proc optnet graph_direction = directed data_links = LinkSetIn out_nodes = NodeSetOut out_links = LinkSetOut; run;
The data set NodeSetOut, shown in Figure 2.6, now contains the nodes that are read from the input link data set. The variable node shows the label associated with each node.
The data set LinkSetOut, shown in Figure 2.7, contains the links that were read from the input link data set. The variables from and to show the associated node labels.
Figure 2.7: Link Data Set of a Simple Directed Graph
| Obs | from | to | weight |
|---|---|---|---|
| 1 | A | B | 1 |
| 2 | A | C | 2 |
| 3 | A | D | 4 |
| 4 | B | C | 1 |
| 5 | B | E | 2 |
| 6 | B | F | 5 |
| 7 | C | E | 1 |
| 8 | D | E | 1 |
| 9 | E | D | 1 |
| 10 | E | F | 2 |
| 11 | F | G | 6 |
| 12 | G | H | 1 |
| 13 | G | I | 1 |
| 14 | H | G | 2 |
| 15 | H | I | 3 |
If you define this graph as undirected, then reciprocal links (for example, ![]() and
and ![]() ) are treated as the same link, and duplicates are removed. PROC OPTNET takes the first occurrence of the link and ignores
the others. By default, GRAPH_DIRECTION=UNDIRECTED, so you can just remove this option to declare the graph as undirected.
) are treated as the same link, and duplicates are removed. PROC OPTNET takes the first occurrence of the link and ignores
the others. By default, GRAPH_DIRECTION=UNDIRECTED, so you can just remove this option to declare the graph as undirected.
proc optnet data_links = LinkSetIn out_nodes = NodeSetOut out_links = LinkSetOut; run;
The progress of the procedure is shown in Figure 2.8. The log now shows the links (and their observation identifiers) that were declared as duplicates and removed.
Figure 2.8: PROC OPTNET Log: Link Data Set of a Simple Undirected Graph
| NOTE: -------------------------------------------------------------------------- |
| NOTE: Running OPTNET version 13.1. |
| NOTE: -------------------------------------------------------------------------- |
| NOTE: Data input used 0.01 (cpu: 0.02) seconds. |
| WARNING: Link (E,D) in observation 9 of the DATA_LINKS= data set is a duplicate |
| and is ignored. |
| WARNING: Link (H,G) in observation 14 of the DATA_LINKS= data set is a |
| duplicate and is ignored. |
| NOTE: The number of nodes in the input graph is 9. |
| NOTE: The number of links in the input graph is 13. |
| NOTE: -------------------------------------------------------------------------- |
| NOTE: Data output used 0.00 (cpu: 0.00) seconds. |
| NOTE: -------------------------------------------------------------------------- |
| NOTE: The data set WORK.NODESETOUT has 9 observations and 1 variables. |
| NOTE: The data set WORK.LINKSETOUT has 13 observations and 3 variables. |
The data set NodeSetOut is equivalent to the one shown in Figure 2.6. However, the new links data set LinkSetOut shown in Figure 2.9 contains two fewer links than before, because duplicates are removed.
Figure 2.9: Link Data Set of a Simple Undirected Graph
| Obs | from | to | weight |
|---|---|---|---|
| 1 | A | B | 1 |
| 2 | A | C | 2 |
| 3 | A | D | 4 |
| 4 | B | C | 1 |
| 5 | B | E | 2 |
| 6 | B | F | 5 |
| 7 | C | E | 1 |
| 8 | D | E | 1 |
| 9 | E | F | 2 |
| 10 | F | G | 6 |
| 11 | G | H | 1 |
| 12 | G | I | 1 |
| 13 | H | I | 3 |
Certain algorithms can perform more efficiently when you specify GRAPH_INTERNAL_FORMAT=THIN in the PROC OPTNET statement. However, when you specify this option, PROC OPTNET does not remove duplicate links. Instead, you should use appropriate DATA steps to clean your data before calling PROC OPTNET.
The DATA_NODES= option in the PROC OPTNET statement defines the data set that contains the list of nodes in the graph. This data set is used to assign node weights.
The nodes data set is expected to contain some combination of the following possible variables:
-
node: the node label (this variable can be numeric or character) -
weight: the node weight (this variable must be numeric) -
weight2: the auxiliary node weight (this variable must be numeric)
You can specify any values that you want for the data set variable names. If you use nonstandard names, you must identify the variables by using the DATA_NODES_VAR statement, as described in the section DATA_NODES_VAR Statement.
The data set that is specified in the DATA_LINKS= option defines the set of nodes that are incident to some link. If the graph contains a node that has no links (called a singleton node), then this node must be defined in the DATA_NODES data set. The following is an example of a graph with three links but four nodes, including a singleton node D:
data NodeSetIn; input label $ @@; datalines; A B C D ; data LinkSetInS; input from $ to $ weight; datalines; A B 1 A C 2 B C 1 ;
If you specify duplicate entries in the node data set, PROC OPTNET takes the first occurrence of the node and ignores the others. A warning is printed to the log.
For some algorithms you might want to process only a subset of the nodes in the input graph. You can accomplish this by using the DATA_NODES_SUB= option in the PROC OPTNET statement. You can use the node subset data set in conjunction with the SHORTPATH statement (see the section Shortest Path. The node subset data set is expected to contain some combination of the following variables:
-
node: the node label (this variable can be numeric or character) -
source: whether to process this node as a source node in shortest path algorithms (this variable must be numeric) -
sink: whether to process this node as a sink node in shortest path algorithms (this variable must be numeric)
The values in the node subset data set determine how to process nodes when the SHORTPATH statement is processed. A value of
0 for the source variable designates that the node is not to be processed as a source; a value of 1 designates that the node is to be processed
as a source. The same values can be used for the sink variable to designate whether the node is to be processed as a sink. The missing indicator (.) can also be used in place
of 0 to designate that a node is not to be processed.
A representative example of a node subset data set that might be used with the graph in Figure 2.5 is as follows:
data NodeSubSetIn; input node $ source sink; datalines; A 1 . F . 1 E 1 . ;
The data set NodeSubSetIn indicates that you want to process the shortest paths from nodes A and E and the shortest paths to node F.