The MVPMODEL Procedure

The PROC MVPMODEL statement invokes the MVPMODEL procedure and optionally identifies input and output data sets, specifies details of the analyses performed, and controls displayed output. Table 12.1 summarizes the options.
Table 12.1: Summary of PROC MVPMODEL Statement Options
|
option |
Description |
|---|---|
|
Computes the principal components from the covariance matrix |
|
|
Performs cross validation to select the number of principal components |
|
|
Specifies the input data set |
|
|
Specifies how observations with missing values are handled |
|
|
Specifies the number of principal components to extract |
|
|
Suppresses centering of process variables before fitting the model |
|
|
Suppresses re-centering and rescaling of process variables before each model is fit in the cross validation |
|
|
Suppresses the display of all output |
|
|
Suppresses scaling of process variables before fitting the model |
|
|
Specifies the output data set |
|
|
Specifies the output data set for loadings (eigenvectors) |
|
|
Requests and specifies details of plots |
|
|
Specifies the prefix for naming principal component score variables in the OUT= data set |
|
|
Specifies the prefix for naming residual variables in the OUT= data set |
|
|
Standardizes the principal component scores |
You can specify the following options.
- COV
-
computes the principal components from the covariance matrix. By default, the correlation matrix is analyzed. The COV option causes variables with large variances to be more strongly associated with components that have large eigenvalues, and it causes variables with small variances to be more strongly associated with components that have small eigenvalues. You should not specify the COV option unless the units in which the variables are measured are comparable or the variables are standardized in some way.
Note: Specifying the COV option has the same effect as specifying the NOSCALE option.
-
CV=ONE
CV=BLOCK <(cv-block-options)>
CV=SPLIT <(cv-split-options)>
CV=RANDOM <(cv-random-options)> -
specifies that cross validation be performed to determine the number of principal components and specifies the method to be used. If you do not specify the CV= option, no cross validation is performed.
In cross validation, the input data are repeatedly divided into a training set, which is used to compute a model, and a test set, which is used to test the model fit. The cross validation that is performed here is along both observations and variables, as described in Eastment and Krzanowski (1982), which is a more detailed version of the "alternative scheme" of Wold (1978). The observations and variables are separately divided into groups. Each test set is the intersection of one observation group and one variable group, so the number of test sets that are used is the product of the number of observation groups and the number of variable groups. See the section Cross Validation for more information.
Note: The CV= option is experimental in this release.
CV=ONE requests one-at-a-time cross validation, in which each observation group contains one observation and each variable group contains one variable. This approach is very computationally intensive because it computes
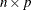 separate principal component models for each potential number of principal components, where n is the number of observations in the input data set and p is the number of process variables.
separate principal component models for each potential number of principal components, where n is the number of observations in the input data set and p is the number of process variables.
CV=BLOCK requests blocked cross validation, in which observation groups consist of blocks of nobs consecutive observations and variable groups consist of blocks of nvar consecutive variables. You can specify the following cv-block-options in parentheses after the CV=BLOCK option:
CV=SPLIT requests split-sample cross validation, in which observation groups are formed by selecting every nobsth observation and variable groups are formed by selecting very nvarth variable. You can specify the following cv-split-options in parentheses after the CV=SPLIT option:
CV=RANDOM requests that observations and variables be assigned to groups randomly. You can specify the following cv-random-options in parentheses after the CV=RANDOM option:
Note: You cannot specify the CV= option together with the NCOMP= option.
- DATA=SAS-data-set
-
specifies the input SAS data set to be analyzed. If the DATA= option is omitted, the procedure uses the most recently created SAS data set.
- MISSING=AVG | NONE
-
specifies how observations with missing values are to be handled in computing the fit. MISSING=AVG specifies that the fit be computed by replacing missing values of a process variable with the average of its nonmissing values. The default is MISSING=NONE, which excludes observations with missing values for any process variables from the analysis.
- NCOMP=n | ALL
-
specifies the number of principal components to extract. The default is
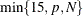 , where p is the number of process variables and N is the number of observations (runs). You can specify NCOMP=ALL to override the limit of 15 principal components. You cannot
specify the NCOMP= option together with the CV=
option. If the number of nonzero eigenvalues of the correlation matrix is less than the number of components specified, p, then the p will be reset to the number of nonzero eigenvalues.
, where p is the number of process variables and N is the number of observations (runs). You can specify NCOMP=ALL to override the limit of 15 principal components. You cannot
specify the NCOMP= option together with the CV=
option. If the number of nonzero eigenvalues of the correlation matrix is less than the number of components specified, p, then the p will be reset to the number of nonzero eigenvalues.
- NOCENTER
-
suppresses centering of the process variables before fitting. This is useful if the variables are already centered and scaled. See the section Centering and Scaling for more information.
- NOCVSTDIZE
-
suppresses re-centering and rescaling of the process variables before each model is fit in the cross validation. See the section Centering and Scaling for more information.
- NOPRINT
-
suppresses the display of all results, both tabular and graphical. This is useful when you want to produce only output data sets.
- NOSCALE
-
suppresses scaling of the process variables before fitting. This is useful if the variables are already centered and scaled.
Note: Specifying the NOSCALE option has the same effect as specifying the COV option.
- OUT=SAS-data-set
-
creates an output data set that contains all the original data from the input data set, principal component scores, and multivariate summary statistics. See the section Output Data Sets for details.
- OUTLOADINGS=SAS-data-set
-
creates an output data set that contains the loadings for the principal components and the eigenvalues of the correlation (or covariance) matrix. See the section Output Data Sets for details.
-
PLOTS <(global-plot-options)> <= plot-request <(options)>>
PLOTS <(global-plot-options)> <= (plot-request <(options)> <... plot-request <(options)>>)> -
controls the plots produced through ODS Graphics. When you specify only one plot request, you can omit the parentheses around the plot request. For example:
plots=none plots=score plots=loadings
ODS Graphics must be enabled before you request plots. For general information about ODS Graphics, see Chapter 21: Statistical Graphics Using ODS in SAS/STAT 13.2 User's Guide.
You can specify the following global-plot-options:
- FLIP
-
interchanges the X-axis and Y-axis dimensions for all score and loading plots.
- NCOMP=n
-
specifies that pairwise score and loading plots be produced for the first n principal components. The default is 5 or the total number of components
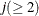 , whichever is smaller. If
, whichever is smaller. If 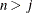 , then the default is NCOMP=j. Be aware that the number of score or loading plots produced (
, then the default is NCOMP=j. Be aware that the number of score or loading plots produced (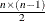 ) grows quadratically as n increases.
) grows quadratically as n increases.
- ONLY
-
suppresses the default plots. Only plots specifically requested are displayed. The default plots are the CV plot, when you specify the CV= option, and the scree and variation-explained plots otherwise.
You can specify the following plot-requests:
- ALL
-
produces all appropriate plots.
- CVPLOT
-
produces a plot that displays the results of the cross validation and R-square analysis. This plot requires that the CV= option be specified and in that case is displayed by default.
- LOADINGS <(loading-options)>
-
produces a matrix of pairwise scatter plots of the principal component loadings. Use NCOMP=n to specify the number of principal components for which plots are produced, and use the FLIP option to interchange the default X-axis and Y-axis dimensions.
You can specify the following loading-options:
- FLIP
-
flips or interchanges the X-axis and Y-axis dimensions of the loading plots. Specify PLOTS=LOADING(FLIP) to flip the X-axis and Y-axis dimensions.
- NCOMP=n
-
specifies that pairwise loading plots be produced for the first n principal components. The default is the value specified by the NCOMP= global-plot-option. If
, then the default is NCOMP=j. Be aware that the number of loading plots produced () grows quadratically as n increases.
-
UNPACKPANEL
UNPACK -
suppresses paneling of loading plots. By default, all the loading plots appear in a single output panel. Specify UNPACKPANEL to display each loading plot in a separate panel.
- NONE
-
suppresses the display of all plots.
- SCORES <(score-options)>
-
produces pairwise scatter plots of the principal component scores. You can use the NCOMP= option to control the number of plots that are displayed.
You can specify the following score-options:
- ALPHA=value
-
specifies the probability used to compute a prediction ellipse that is overlaid on the score plot. The default is 0.05. If you specify the ALPHA= option, you do not need to specify the ELLIPSE option.
- ELLIPSE
-
requests that a prediction ellipse be overlaid on the principal component score plots. The probability that a new observation falls outside the prediction ellipse is specified by the ALPHA= option.
- FLIP
-
flips or interchanges the X-axis and Y-axis dimensions of the score plots. Specify PLOTS=SCORES(FLIP) to flip the X-axis and Y-axis dimensions.
- GROUP=variable
-
specifies a variable in the input data set used to group the points on the score plots. Points with different GROUP= variable values are plotted using different markers and colors to distinguish the groups.
- LABELS=ON | OFF | OUTSIDE
-
specifies which points in the score plots to label. Specify LABELS=ON to label all points and LABELS=OFF to label none of the points. Points are labeled with the values of the first variable listed in the ID statement, or the observation number if no ID statement is specified.
If you specify the ELLIPSE and UNPACKPANEL options, you can specify LABELS=OUTSIDE to label only the points outside the confidence ellipse.
The default is ON if you specify UNPACKPANEL and OFF otherwise.
- NCOMP=n
-
specifies that pairwise score plots be produced for the first n principal components. The default is the value specified by the NCOMP= global-plot-option. If
, then the default is NCOMP=j. Be aware that the number of loading plots produced () grows quadratically as n increases.
- UNPACKPANEL
-
suppresses paneling of score plots. By default, all the score plots appear in a single output panel. Specify UNPACKPANEL to display each score plot in a separate panel.
-
SCREE <UNPACK>
EIGEN
EIGENVALUE -
produces a scree plot of eigenvalues and a variance-explained plot. By default, both plots are produced in a panel. Specify PLOTS= SCREE(UNPACKPANEL) to display each plot in a separate panel. This plot is produced by default unless you specify the CV= option.
- PREFIX=name
-
specifies a prefix for naming the principal component scores in the OUT= data set. By default, the names are
Prin1,Prin2, …,Prinj. If you specify PREFIX=ABC, the components are namedABC1,ABC2,ABC3, and so on. The number of characters in the prefix plus the number of digits in j should not exceed the current name length defined by the VALIDVARNAME= system option. - RPREFIX=name
-
specifies a prefix for naming the residual variables in the OUT= data set. The default is
R_. Residual variable names are formed by appending process variable names to the prefix.If the length of the resulting residual variable exceeds the maximum name length defined by the VALIDVARNAME= system option, characters are removed from the middle of the process variable name before it is appended to the residual prefix. For example, if you specify RPREFIX=Residual_, the maximum variable name length is 32, and there is a process variable named
PrimaryThermometerReading, then the corresponding residual variable name isResidual_PrimaryThermeterReading. - STDSCORES
-
standardizes the principal component scores in the OUT= data set to unit variance. If you omit the STDSCORES option, the variances of the scores are equal to the corresponding eigenvalues. STDSCORES has no effect on the eigenvalues themselves.