The BCHOICE Procedure (Experimental)

RANDOM random-effects </ options> ;
The RANDOM statement defines the random effects in the choice model. You can use this statement to specify traditional variance component models and to specify random coefficients, which can be classification or continuous. You can specify only one RANDOM statement. Include the TYPE= option to define the covariance structure. PROC BCHOICE does not include the intercept in the RANDOM statement.
Table 27.4 summarizes the options available in the RANDOM statement. All options are subsequently discussed in alphabetical order.
Table 27.4: Summary of RANDOM Statement Options
|
Option |
Description |
|---|---|
|
Specifies the prior distribution for the covariance of the random effects |
|
|
Displays solutions of the random effects |
|
|
Suppresses the output of the posterior samples of random effects to the OUTPOST= data set |
|
|
Models the prior mean of the random effects |
|
|
Identifies the subjects in the model |
|
|
Specifies the covariance structure |
You can specify the following options in the RANDOM statement after a slash (/).
- COVPRIOR=IWISHART<(options)>
-
specifies an inverse Wishart prior distribution, IWISHART(a,b), for the covariance matrix of the random effects.
You can specify the following options, enclosed in parentheses:
- DF=a
-
specifies the degrees of freedom of the inverse Wishart distribution. The default is the dimension of the covariance matrix of the random effects plus 3.
- SCALE=b
-
specifies
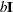 for the scale parameter of the inverse Wishart distribution, where
for the scale parameter of the inverse Wishart distribution, where 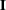 is the identity matrix. The default is the dimension of the covariance matrix of the random effects plus 3.
is the identity matrix. The default is the dimension of the covariance matrix of the random effects plus 3.
-
MONITOR
MONITOR=(numeric-list)
MONITOR=RANDOM (number) -
outputs results for the individual-level random-effects parameters. (By default, PROC BCHOICE does not output results for individual-level random-effects parameters.) You can monitor a subset of the random-effects parameters. You can provide a numeric list of the SUBJECT indexes, or PROC BCHOICE can randomly choose a subset of all subjects for you.
To monitor a list of random-effects parameters for certain subjects, you can provide their indexes as follows:
random x / subject=index monitor=(1 to 5 by 2 23 57);
PROC BCHOICE outputs results of random effects for subjects 1, 3, 5, 23, and 57. PROC BCHOICE can also randomly choose a subset of all the subjects to monitor, if you submit a statement such as the following:
random x / subject=index monitor=(random(12));
PROC BCHOICE outputs results of random effects for 12 randomly selected subjects. You control the sequence of the random indexes by specifying the SEED= option in the PROC BCHOICE statement.
When you specify the MONITOR option, it uses the specification of the STATISTICS= and PLOTS= options in the PROC BCHOICE statement. By default, PROC BCHOICE outputs all the posterior samples of all random-effects parameters to the OUTPOST= output data set. You can use the NOOUTPOST option to suppress the saving of the random-effects parameters.
- NOOUTPOST
-
suppresses the output of the posterior samples of random-effects parameters to the OUTPOST= data set. In models that have a large number of random-effects parameters (for example, tens of thousands), PROC BCHOICE can run faster if it does not save the posterior samples of the random-effects parameters.
When you specify both the NOOUTPOST option and the MONITOR option, PROC BCHOICE outputs the list of variables that are monitored.
The maximum number of variables that can be saved to an OUTPOST= data set is 32,767. If you run a large-scale random-effects model in which the number of parameters exceeds this limit, the NOOUTPOST option is invoked automatically and PROC BCHOICE does not save the random-effects draws to the posterior output data set. You can use the MONITOR option to select a subset of the parameters to store in the OUTPOST= data set.
- REMEAN
-
models the mean of the random effects, so that
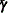 is estimated. You can also model the prior mean of the random effects as a function of individual demographic variables.
Rossi, McCulloch, and Allenby (1996) and Rossi, Allenby, and McCulloch (2005) propose adding another layer of flexibility to the random-effects-only model by allowing heterogeneity that is driven by
observable (demographic) characteristics of the individuals. The following REMEAN=(AGE GENDER) option in the RANDOM statement
estimates the mean of the random effect,
is estimated. You can also model the prior mean of the random effects as a function of individual demographic variables.
Rossi, McCulloch, and Allenby (1996) and Rossi, Allenby, and McCulloch (2005) propose adding another layer of flexibility to the random-effects-only model by allowing heterogeneity that is driven by
observable (demographic) characteristics of the individuals. The following REMEAN=(AGE GENDER) option in the RANDOM statement
estimates the mean of the random effect, X, and models the mean as a function ofAgeandGender:random X / subject=Index remean=(Age Gender);
-
SUBJECT=effect
SUB=effect -
identifies the subjects in the model. PROC BCHOICE assumes complete independence across subjects; thus, for the RANDOM statement, the SUBJECT= option produces a block-diagonal structure that has identical blocks. Specifying a subject effect is equivalent to nesting all other effects in the RANDOM statement within the subject effect.
The effect can be continuous variables. PROC BCHOICE does not sort by the values of the continuous variable; rather, it considers the data to be from a new subject or group whenever the value of the continuous variable changes from the previous observation.
- TYPE=UN | VC
-
specifies the covariance structure. Although a variety of structures are available, most applications call for either TYPE=VC or TYPE=UN. The TYPE=VC (variance components) option, which is the default structure, models a different variance component for each random effect. The TYPE=UN (unstructured) specifies a full structured covariance matrix for the random effects. The unstructured form accommodates any pattern of correlation between the random effects in addition to fitting a different variance component for each random effect.