The MI Procedure
- Overview
- Getting Started
-
Syntax

-
DetailsDescriptive StatisticsEM Algorithm for Data with Missing ValuesStatistical Assumptions for Multiple ImputationMissing Data PatternsImputation MethodsMonotone Methods for Data Sets with Monotone Missing PatternsMonotone and FCS Regression MethodsMonotone and FCS Predictive Mean Matching MethodsMonotone and FCS Discriminant Function MethodsMonotone and FCS Logistic Regression MethodsMonotone Propensity Score MethodFCS Methods for Data Sets with Arbitrary Missing PatternsChecking Convergence in FCS MethodsMCMC Method for Arbitrary Missing Multivariate Normal DataProducing Monotone Missingness with the MCMC MethodMCMC Method SpecificationsChecking Convergence in MCMCInput Data SetsOutput Data SetsCombining Inferences from Multiply Imputed Data SetsMultiple Imputation EfficiencyImputer’s Model Versus Analyst’s ModelParameter Simulation versus Multiple ImputationSensitivity Analysis for the MAR AssumptionMultiple Imputation with Pattern-Mixture ModelsSpecifying Sets of Observations for Imputation in Pattern-Mixture ModelsAdjusting Imputed Values in Pattern-Mixture ModelsSummary of Issues in Multiple ImputationODS Table NamesODS Graphics
-
ExamplesEM Algorithm for MLEMonotone Propensity Score MethodMonotone Regression MethodMonotone Logistic Regression Method for CLASS VariablesMonotone Discriminant Function Method for CLASS VariablesFCS Method for Continuous VariablesFCS Method for CLASS VariablesFCS Method with Trace PlotMCMC MethodProducing Monotone Missingness with MCMCChecking Convergence in MCMCSaving and Using Parameters for MCMCTransforming to NormalityMultistage ImputationCreating Control-Based Pattern Imputation in Sensitivity AnalysisAdjusting Imputed Continuous Values in Sensitivity AnalysisAdjusting Imputed Classification Levels in Sensitivity AnalysisAdjusting Imputed Values with Parameters in a Data Set
- References
The logistic regression method is another imputation method available for classification variables. In the logistic regression method, a logistic regression model is fitted for a classification variable with a set of covariates constructed from the effects, where the classification variable is an ordinal response or a nominal response variable.
In the MI procedure, ordered values are assigned to response levels in ascending sorted order. If the response variable Y takes values in ![]() , then for ordinal response models, the cumulative model has the form
, then for ordinal response models, the cumulative model has the form
where ![]() are K-1 intercept parameters, and
are K-1 intercept parameters, and ![]() is the vector of slope parameters.
is the vector of slope parameters.
For nominal response logistic models, where the K possible responses have no natural ordering, the generalized logit model has the form
where the ![]() are K-1 intercept parameters, and the
are K-1 intercept parameters, and the ![]() are K-1 vectors of slope parameters.
are K-1 vectors of slope parameters.
For a binary classification variable, based on the fitted regression model, a new logistic regression model is simulated from the posterior predictive distribution of the parameters and is used to impute the missing values for each variable (Rubin, 1987, pp. 167–170).
For a binary variable Y with responses 1 and 2, a logistic regression model is fitted using observations with observed values for the imputed variable
Y:
where ![]() are covariates for
are covariates for Y, ![]() , and
, and ![]()
The fitted model includes the regression parameter estimates ![]() and the associated covariance matrix
and the associated covariance matrix ![]() .
.
The following steps are used to generate imputed values for a binary variable Y with responses 1 and 2:
-
New parameters
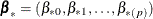 are drawn from the posterior predictive distribution of the parameters.
are drawn from the posterior predictive distribution of the parameters.
![\[ \bbeta _{*} = \hat{\bbeta } + \mb {V}_{h}’ \mb {Z} \]](images/statug_mi0164.png)
where
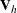 is the upper triangular matrix in the Cholesky decomposition,
is the upper triangular matrix in the Cholesky decomposition, 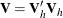 , and
, and 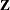 is a vector of
is a vector of 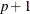 independent random normal variates.
independent random normal variates.
-
For an observation with missing
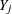 and covariates
and covariates 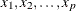 , compute the predicted probability that
, compute the predicted probability that Y= 1:![\[ p_1 = \frac{\mr {exp}({\mu }_1)}{1+\mr {exp}({\mu }_1)} \]](images/statug_mi0169.png)
where
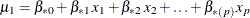 .
.
-
Draw a random uniform variate, u, between 0 and 1. If the value of u is less than
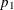 , impute
, impute Y= 1; otherwise imputeY= 2.
The binary logistic regression imputation method can be extended to include the ordinal classification variables with more than two levels of responses, and the nominal classification variables. The LINK=LOGIT and LINK=GLOGIT options can be used to specify the cumulative logit model and the generalized logit model, respectively. The options ORDER= and DESCENDING can be used to specify the sort order for the levels of the imputed variables.
For an ordinal classification variable, based on the fitted regression model, a new logistic regression model is simulated from the posterior predictive distribution of the parameters and is used to impute the missing values for each variable.
For a variable Y with ordinal responses 1, 2, …, K, a logistic regression model is fitted using observations with observed values for the
imputed variable Y:
where ![]() are covariates for
are covariates for Y and ![]() .
.
The fitted model includes the regression parameter estimates ![]() and
and ![]() , and their associated covariance matrix
, and their associated covariance matrix ![]() .
.
The following steps are used to generate imputed values for an ordinal classification variable Y with responses 1, 2, …, K:
-
New parameters
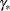 are drawn from the posterior predictive distribution of the parameters.
are drawn from the posterior predictive distribution of the parameters.
![\[ \gamma _{*} = \hat{\gamma } + \mb {V}_{h}’ \mb {Z} \]](images/statug_mi0177.png)
where
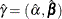 , is the upper triangular matrix in the Cholesky decomposition, , and is a vector of
, is the upper triangular matrix in the Cholesky decomposition, , and is a vector of 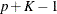 independent random normal variates.
independent random normal variates.
-
For an observation with missing
Yand covariates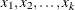 , compute the predicted cumulative probability for
, compute the predicted cumulative probability for 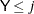 :
:
![\[ p_ j= \mr {pr}(\Variable{Y} \leq j) = \frac{ e^{\alpha _ j + \mb {x} \bbeta } }{ e^{\alpha _ j + \mb {x} \bbeta } + 1} \]](images/statug_mi0181.png)
-
Draw a random uniform variate, u, between 0 and 1, then impute
![\[ Y = \left\{ \begin{array}{ll} 1 & \mr {if} \; \Mathtext{u} < p_{1} \vspace{0.125in} \\ k & \mr {if} \; p_{k-1} \leq \Mathtext{u} < p_{k} \vspace{0.125in} \\ K & \mr {if} \; p_{K-1} \leq \Mathtext{u} \end{array} \right. \]](images/statug_mi0182.png)
For a nominal classification variable, based on the fitted regression model, a new logistic regression model is simulated from the posterior predictive distribution of the parameters and is used to impute the missing values for each variable.
For a variable Y with nominal responses 1, 2, …, K, a logistic regression model is fitted using observations with observed values for the
imputed variable Y:
where ![]() are covariates for
are covariates for Y and ![]() .
.
The fitted model includes the regression parameter estimates ![]() and
and ![]() , and their associated covariance matrix
, and their associated covariance matrix ![]() , where
, where ![]() ,
,
The following steps are used to generate imputed values for a nominal classification variable Y with responses 1, 2, …, K:
-
New parameters
are drawn from the posterior predictive distribution of the parameters.
where
, is the upper triangular matrix in the Cholesky decomposition, , and is a vector of independent random normal variates.
-
For an observation with missing
Yand covariates, compute the predicted probability for Y= j, j=1, 2, …, K-1:![\[ \mr {pr}(\Variable{Y}=j) = \frac{ e^{ \alpha _ j + \mb {x} \bbeta _ j } }{ \sum _{k=1}^{K-1} {e^{ \alpha _ k + \mb {x} \bbeta _ k }} + 1 } \]](images/statug_mi0187.png)
and
![\[ \mr {pr}(\Variable{Y}=K) = \frac{ 1 }{ \sum _{k=1}^{K-1} {e^{ \alpha _ k + \mb {x} \bbeta _ k }} + 1 } \]](images/statug_mi0188.png)
-
Compute the cumulative probability for
:
![\[ P_ j= \sum _{k=1}^{j} \mr {pr}(\Variable{Y}=k) \]](images/statug_mi0189.png)
-
Draw a random uniform variate, u, between 0 and 1, then impute