The PLAN Procedure

The OUTPUT statement applies only to the last plan generated. If you use PROC PLAN interactively, the OUTPUT statement for a given plan must be immediately preceded by the FACTORS statement (and the TREATMENTS statement, if appropriate) for the plan.
See Output Data Sets for more information about how output data sets are constructed.
You can specify the following options in the OUTPUT statement:
When you specify only an OUT= data set, the form for each factor-value-setting specification is one of the following:
or
where
- factor-name
-
is a factor in the last FACTORS statement preceding the OUTPUT statement.
- NVALS=
-
lists n numeric values for the factor. By default, the procedure uses NVALS=(1 2 3
 ).
).
- CVALS=
-
lists n character strings for the factor. Each string can have up to 40 characters, and each string must be enclosed in quotes. Caution: When you use the CVALS= option, the variable created in the output data set has a length equal to the length of the longest string given as a value; shorter strings are padded with trailing blanks. For example, the values output for the first level of a two-level factor with the following two different specifications are not the same.
CVALS=('String 1' "String 2") CVALS=('String 1' "A longer string")The value output with the second specification is ’String 1’ followed by seven blanks. In order to match two such values (for example, when merging two plans), you must use the TRIM function in the DATA step (see SAS Functions and CALL Routines: Reference).
- ORDERED | RANDOM
-
specifies how values (those given with the NVALS= or CVALS= option, or the default values) are associated with the levels of a factor (the integers
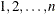 ). The default association type is ORDERED, for which the first value specified is output for a factor level setting of 1,
the second value specified is output for a level of 2, and so on. You can also specify an association type of RANDOM, for
which the levels are associated with the values in a random order. Specifying RANDOM is useful for randomizing crossed experiments
(see the section Randomizing Designs).
). The default association type is ORDERED, for which the first value specified is output for a factor level setting of 1,
the second value specified is output for a level of 2, and so on. You can also specify an association type of RANDOM, for
which the levels are associated with the values in a random order. Specifying RANDOM is useful for randomizing crossed experiments
(see the section Randomizing Designs).
The following statements give an example of using the OUTPUT statement with only an OUT= data set and with both the NVALS= and CVALS= specifications.
proc plan seed=27371;
factors a=6 ordered b=3;
output out=design a nvals=(10 to 60 by 10)
b cvals=('HSX' 'SB2' 'DNY');
run;
The DESIGN data set contains two variables, a and b. The values of the variable a are 10 when factor a equals 1, 20 when factor a equals 2, and so on. Values of the variable b are ‘HSX’ when factor b equals 1, ‘SB2’ when factor b equals 2, and ‘DNY’ when factor b equals 3.
If you specify an input data set with DATA= , then PROC PLAN assumes that each factor in the last plan generated corresponds to a variable in the input set. If the variable name is different from the name of the factor to which it corresponds, the two can be associated in the values specification by
Then, the NVALS= or CVALS= specification can be used. The values given by NVALS= or CVALS= specify the input values as well as the output values for the corresponding variable.
Since the procedure assumes that the collection of input factor values constitutes a plan position description (see the section Output Data Sets), the values must correspond to integers less than or equal to m, the number of values selected for the associated factor. If any input values do not correspond, then the collection does not define a plan position, and the corresponding observation is output without changing the values of any of the factor variables.
The following statements demonstrate the use of factor-value-settings. The input SAS data set a contains variables Day and Hour, which are renamed Block and Plot, respectively.
proc plan seed=27371;
factors Block=7 Plot=6;
output data=a out=b
Day = Block cvals=('Mon' 'Tue' 'Wed' 'Thu'
'Fri' 'Sat' 'Sun' )
Hour = Plot;
run;
For another example of using both a DATA= and OUT= data set, see the section Randomly Assigning Subjects to Treatments.