The GLM Procedure
-
Overview

-
Getting Started
-
Syntax
-
DetailsStatistical Assumptions for Using PROC GLMSpecification of EffectsUsing PROC GLM InteractivelyParameterization of PROC GLM ModelsHypothesis Testing in PROC GLMEffect Size Measures for F Tests in GLMAbsorptionSpecification of ESTIMATE ExpressionsComparing GroupsMultivariate Analysis of VarianceRepeated Measures Analysis of VarianceRandom-Effects AnalysisMissing ValuesComputational ResourcesComputational MethodOutput Data SetsDisplayed OutputODS Table NamesODS Graphics
-
ExamplesRandomized Complete Blocks with Means Comparisons and ContrastsRegression with Mileage DataUnbalanced ANOVA for Two-Way Design with InteractionAnalysis of CovarianceThree-Way Analysis of Variance with ContrastsMultivariate Analysis of VarianceRepeated Measures Analysis of VarianceMixed Model Analysis of Variance with the RANDOM StatementAnalyzing a Doubly Multivariate Repeated Measures DesignTesting for Equal Group VariancesAnalysis of a Screening Design
- References
OUTPUT <OUT=SAS-data-set> keyword=names <…keyword=names> <option> ;
The OUTPUT statement creates a new SAS data set that saves diagnostic measures calculated after fitting the model. At least one specification of the form keyword=names is required.
All the variables in the original data set are included in the new data set, along with variables created in the OUTPUT statement. These new variables contain the values of a variety of diagnostic measures that are calculated for each observation in the data set. If you want to create a SAS data set in a permanent library, you must specify a two-level name. For more information about permanent libraries and SAS data sets, see SAS Language Reference: Concepts.
Details on the specifications in the OUTPUT statement follow.
- keyword=names
-
specifies the statistics to include in the output data set and provides names to the new variables that contain the statistics. Specify a keyword for each desired statistic (see the following list of keywords), an equal sign, and the variable or variables to contain the statistic.
In the output data set, the first variable listed after a keyword in the OUTPUT statement contains that statistic for the first dependent variable listed in the MODEL statement; the second variable contains the statistic for the second dependent variable in the MODEL statement, and so on. The list of variables following the equal sign can be shorter than the list of dependent variables in the MODEL statement. In this case, the procedure creates the new names in order of the dependent variables in the MODEL statement. See the section Examples.
The keywords allowed and the statistics they represent are as follows:
- COOKD
- COVRATIO
-
standard influence of observation on covariance of parameter estimates
- DFFITS
- H
- LCL
-
lower bound of a 100(1 - p)% confidence interval for an individual prediction. The p-level is equal to the value of the ALPHA= option in the OUTPUT statement or, if this option is not specified, to the ALPHA= option in the PROC GLM statement. If neither of these options is set, then p = 0.05 by default, resulting in the lower bound for a 95% confidence interval. The interval also depends on the variance of the error, as well as the variance of the parameter estimates. For the corresponding upper bound, see the UCL keyword.
- LCLM
-
lower bound of a 100(1 - p)% confidence interval for the expected value (mean) of the predicted value. The p-level is equal to the value of the ALPHA= option in the OUTPUT statement or, if this option is not specified, to the ALPHA= option in the PROC GLM statement. If neither of these options is set, then p = 0.05 by default, resulting in the lower bound for a 95% confidence interval. For the corresponding upper bound, see the UCLM keyword.
- PREDICTED | P
- PRESS
-
residual for the ith observation that results from dropping it and predicting it on the basis of all other observations. This is the residual divided by
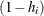 , where
, where 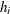 is the leverage, defined previously.
is the leverage, defined previously.
- RESIDUAL | R
- RSTUDENT
- STDI
- STDP
- STDR
- STUDENT
-
studentized residuals, the residual divided by its standard error
- UCL
-
upper bound of a 100(1 - p)% confidence interval for an individual prediction. The p-level is equal to the value of the ALPHA= option in the OUTPUT statement or, if this option is not specified, to the ALPHA= option in the PROC GLM statement. If neither of these options is set, then p = 0.05 by default, resulting in the upper bound for a 95% confidence interval. The interval also depends on the variance of the error, as well as the variance of the parameter estimates. For the corresponding lower bound, see the LCL keyword.
- UCLM
-
upper bound of a 100(1 - p)% confidence interval for the expected value (mean) of the predicted value. The p-level is equal to the value of the ALPHA= option in the OUTPUT statement or, if this option is not specified, to the ALPHA= option in the PROC GLM statement. If neither of these options is set, then p = 0.05 by default, resulting in the upper bound for a 95% confidence interval. For the corresponding lower bound, see the LCLM keyword.
- OUT=SAS-data-set
-
gives the name of the new data set. By default, the procedure uses the
DATAnconvention to name the new data set.The following option is available in the OUTPUT statement and is specified after a slash (/):
- ALPHA=p
-
specifies the level of significance p for
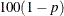 % confidence intervals. By default, p is equal to the value of the ALPHA= option in the PROC GLM statement or 0.05 if that option is not specified. You can use values between 0 and 1.
% confidence intervals. By default, p is equal to the value of the ALPHA= option in the PROC GLM statement or 0.05 if that option is not specified. You can use values between 0 and 1.
See Chapter 4: Introduction to Regression Procedures, and the section Influence Statistics in Chapter 83: The REG Procedure, for details on the calculation of these statistics.
The following statements show the syntax for creating an output data set with a single dependent variable.
proc glm; class a b; model y=a b a*b; output out=new p=yhat r=resid stdr=eresid; run;
These statements create an output data set named new. In addition to all the variables from the original data set, new contains the variable yhat, with values that are predicted values of the dependent variable y; the variable resid, with values that are the residual values of y; and the variable eresid, with values that are the standard errors of the residuals.
The following statements show a situation with five dependent variables.
proc glm; by group; class a; model y1-y5=a x(a); output out=pout predicted=py1-py5; run;
The data set pout contains five new variables, py1 through py5. The values of py1 are the predicted values of y1; the values of py2 are the predicted values of y2; and so on.
For more information about the data set produced by the OUTPUT statement, see the section Output Data Sets.