The MI Procedure
- Overview
- Getting Started
-
Syntax

-
DetailsDescriptive StatisticsEM Algorithm for Data with Missing ValuesStatistical Assumptions for Multiple ImputationMissing Data PatternsImputation MethodsMonotone Methods for Data Sets with Monotone Missing PatternsMonotone and FCS Regression MethodsMonotone and FCS Predictive Mean Matching MethodsMonotone Propensity Score MethodMonotone and FCS Discriminant Function MethodsMonotone and FCS Logistic Regression MethodsFCS Methods for Data Sets with Arbitrary Missing PatternsChecking Convergence in FCS MethodsMCMC Method for Arbitrary Missing Multivariate Normal DataProducing Monotone Missingness with the MCMC MethodMCMC Method SpecificationsChecking Convergence in MCMCInput Data SetsOutput Data SetsCombining Inferences from Multiply Imputed Data SetsMultiple Imputation EfficiencyImputer’s Model Versus Analyst’s ModelParameter Simulation versus Multiple ImputationSummary of Issues in Multiple ImputationODS Table NamesODS Graphics
-
ExamplesEM Algorithm for MLEMonotone Propensity Score MethodMonotone Regression MethodMonotone Logistic Regression Method for CLASS VariablesMonotone Discriminant Function Method for CLASS VariablesFCS Method for Continuous VariablesFCS Method for CLASS VariablesFCS Method with Trace PlotMCMC MethodProducing Monotone Missingness with MCMCChecking Convergence in MCMCSaving and Using Parameters for MCMCTransforming to NormalityMultistage Imputation
- References
Monotone Propensity Score Method
The propensity score method is another imputation method available for continuous variables when the data set has a monotone missing pattern.
A propensity score is generally defined as the conditional probability of assignment to a particular treatment given a vector of observed covariates (Rosenbaum and Rubin, 1983). In the propensity score method, for a variable with missing values, a propensity score is generated for each observation to estimate the probability that the observation is missing. The observations are then grouped based on these propensity scores, and an approximate Bayesian bootstrap imputation (Rubin, 1987, p. 124) is applied to each group (Lavori, Dawson, and Shera, 1995).
The propensity score method uses the following steps to impute values for variable ![]() with missing values:
with missing values:
-
Creates an indicator variable
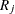 with the value 0 for observations with missing
with the value 0 for observations with missing 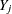 and 1 otherwise.
and 1 otherwise.
-
Fits a logistic regression model
![\[ \mr {logit} (p_{j}) = {\beta }_{0} + {\beta }_{1} \, X_{1} + {\beta }_{2} \, X_{2} + \ldots + {\beta }_{k} \, X_{k} \]](images/statug_mi0125.png)
where
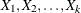 are covariates for ,
are covariates for , 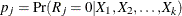 , and
, and 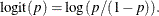
-
Creates a propensity score for each observation to estimate the probability that it is missing.
-
Divides the observations into a fixed number of groups (typically assumed to be five) based on these propensity scores.
-
Applies an approximate Bayesian bootstrap imputation to each group. In group k, suppose that
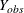 denotes the
denotes the 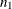 observations with nonmissing values and
observations with nonmissing values and 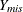 denotes the
denotes the 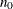 observations with missing . The approximate Bayesian bootstrap imputation first draws observations randomly with replacement from to create a new data set
observations with missing . The approximate Bayesian bootstrap imputation first draws observations randomly with replacement from to create a new data set 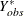 . This is a nonparametric analog of drawing parameters from the posterior predictive distribution of the parameters. The process
then draws the values for randomly with replacement from .
. This is a nonparametric analog of drawing parameters from the posterior predictive distribution of the parameters. The process
then draws the values for randomly with replacement from .
Steps 1 through 5 are repeated sequentially for each variable with missing values.
The propensity score method was originally designed for a randomized experiment with repeated measures on the response variables. The goal was to impute the missing values on the response variables. The method uses only the covariate information that is associated with whether the imputed variable values are missing; it does not use correlations among variables. It is effective for inferences about the distributions of individual imputed variables, such as a univariate analysis, but it is not appropriate for analyses that involve relationship among variables, such as a regression analysis (Schafer, 1999, p. 11). It can also produce badly biased estimates of regression coefficients when data on predictor variables are missing (Allison, 2000).